ART + AI — Generating African Masks using (Tensorflow and TPUs)

In August 2018, I had the opportunity to attend the 2018 Deep Learning Indaba where Google generously provided access to TPUs (v2) to all participants! I finally came around to spending some time getting familiar with running ML experiments on TPUs and started out with training a GAN to generate images based on a custom dataset I have been curating - the African masks dataset. TPUs provide some serious compute horsepower (at par with high end GPUs) that enable fast turnaround for training experiments . Having access to a TPU allowed me explore some questions related to training GANs - e.g. how much data is enough data? How might image size affect generated output? How important is data quality (e.g efforts to curate your dataset?) How novel are the generated samples? etc. In this post, I provide a walk through steps in I took training the GAN, results and interesting observations.
Want to try out an interactive demo with the generated images and explore their similarity with images in the training dataset? The demo is here. Have access to a TPU and want to train a GAN on your custom data? Code used in this project are on GitHub, including trained models for generating masks.
.")
Web demo interface allows you view generated images and most similar from the dataset based on features extracted from a VGG network (block1_pool and block5_pool).
Tensorflow on TPUs
To run TensorFlow code on TPUs, the most important piece is related to using the TPU version of the fairly well-designed Estimator API. Estimators encapsulate the following aspects of the training loop: training, evaluation, prediction, export for serving. For the most part, Tensorflow code written using this API (btw, keras models can be converted to the estimator API easily) can be run on TPUs by replacing the regular Estimator with a TPU Estimator. Even better, the TPUEstimator will work on a CPU and GPU (you should set the use_tpu flags), allowing easy testing on a local machine before deploying to a TPU cluster.
Luckily, I did not have to implement DCGANs from scratch as Tensorflow does provide some sample code. However, the sample supports generation of 32px images (cifar dataset) and my main task was to extend the model to support large image sizes (64px, 128px), similar to work done with artDCGAN. This was achieved mainly by extending (adding layers to) the generator and discriminator within the DCGAN model. The trickiest part here was to ensure size consistency .i.e. ensure input/output from each layer or function matches the expected shape and size.
Generative Adversarial Networks (GANs)
GANs are a form of deep neural network that are particularly useful for density estimating. GANs are generative in that they learn a distribution (the training image dataset) and can generate "novel" samples that lie within this distribution. They are adversarial because they are structured as a game in which two neural networks (a generator G and a discriminator D) compete - G learns to generate fake images (by estimating the image data distribution) and the D learns to tell apart real from fake images (probability that the image comes from the distribution or from G).
As the game progresses, the G learns to create "convincing" images which Dcannot tell apart from real images. It is expected that G learns all of the salient "modes" within the data and covers all of them when generating new images. E.g. a GAN trained on the Cifar10 dataset should generate images from all 10 categories (cars, trucks, aeroplanes etc). Advances in this area of research have focused on finding good criteria for both networks to evaluate themselves (loss functions), better architectures which address several known issues (e.g. one network overpowering the other, failing to learn all "modes" of the data distribution), generation of realistic/high resolution images etc.
For this project, an unconditional DCGAN[1] or deep convolutional GAN architecture is used given its architectural choices that make it stable during training. Tensorflow provides example code on training a DCGAN (CIFAR, MNIST) with TPUs which was extended for this experiment.
Data Preparation and Training
For this project, I used the African Masks dataset - a manually curated set of ~9300 images depicting African Masks (I am still curating this dataset but plan to release it soon).
One thing to note is that this dataset contains diverse "modes" of images (i.e. masks of many different, shapes, textures etc) as opposed to well defined datasets like CelebA which contain only faces with limited variations. It would be interesting to see how the GAN attempts to learn modes from this dataset and its interpretations of these modes. The goal is not to generate a perfectly realistic mask (a common objective in recent GAN work) but more towards observing any creative or artistic elements encoded in the resulting GAN.
Training on TPUs
For training, the first step is to resize, crop each image and then convert to TFrecords. The script used for this is provided within the projects's Github repo. While we do not care about labels for unconditional GANs, the script uses directory names as labels (similar to torchvision imageFolder).
Two versions of the DCGAN model were trained to generate 64px and 128px images respectively. This involved changing the input function to reflect new input sizes, and then extending the model ( adding layers to D and G) to match 64px and 128px generation. Other parameters were mostly similar for both models - train steps: 15k, batch size:1024, fixed noise dimension:100, learning rate: 0.0002 (for D and G).
Some Interesting Observations
Image Generation Size
Images generated within in the 64px regime provided better diversity compared to the 128px regime. While 128px images clearly had higher quality , they appeared to suffer from partial model collapse. This is likely due to the dataset being insufficient to train such a large model (I also experimented with longer training time for the 128px model, but this did not help).


How Much Data is Enough Data?
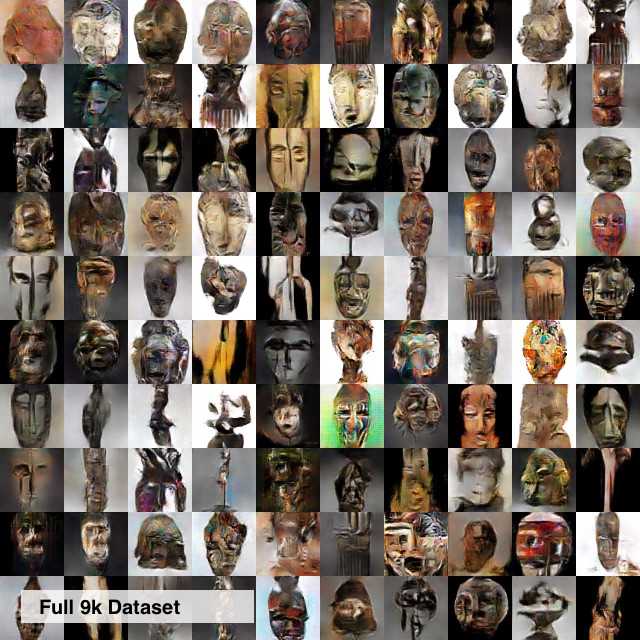
I found that in practice, a dataset with as low as 2k -3k images would generate some form of "results". To further explore how dataset size impacts generated results, I extracted a random sample of the mask dataset (3k images, 64px) and trained a model. The main observation here is that there is more occurrence of partial "mode collapse" (this problem is well explained here) and reduced diversity in the generated images. Screenshot below contains the images generated from two models trained with the same parameters but using the 3k dataset and the full 9k dataset. Other research projects (see here) appear to train GANs with decent results between 6k and 9k images. My intuition so far is that for a dataset with some level of relatedness, the GAN is able to start learning interesting modes from about 6k-9k images. I will be updating this section as I run more experiments.

Does a noisy dataset matter?
Curating a dataset can be tedious. Initial image search results may contain unusable data (e.g. pictures of pictures, sketches, 2D images, unrelated images tagged as masks etc). This raises some related questions - how does the present of noisy images affect the quality of images generated by a GAN. To explore this, I trained a model using 13k images (uncurated results from a web search) and visually compared results to one from my manually curated 9k images.

64px images generated with similar models but left uses a 3k dataset and right uses the full 9k images in the dataset. Images generated using the 3k image dataset shows lower diversity with several similar/repeated images (highlighted).
In my case, it appears that having additional images (about 3k, 20% of the whole dataset) that were not curated did not completely prevent the generator from exploring interesting modes in the data (image above to the left). However, there were some random images (highlighted in red) that clearly did not have the expected texture or patterns expected of an African mask. To explore this some more, I assembled a dataset on 29k images of "teacups" and trained a model. Figure below shows results (trained up to 25k steps and 32k steps). While there are some particularly interesting looking images, it is still unclear if we would do much better by curating the dataset.

What did the GAN Learn?
This was perhaps the most interesting aspect of this experiment. It focuses on the well researched question of "what does the GAN actually learn?", but more from a qualitative perspective. One approach is to observe similarities between generated images and images in the dataset. In their paper, Karras et al [2] compute this using L1 distance of pixels between these images. This approach has been criticized as too simplistic (does not exploit any knowledge of image content). To compute similarity, a pre-trained CNN (VGG16, Simonyan and Zisserman 2016) is used as a feature extractor. Similarity is then computed as a measure of the cosine distance between generated images and images in the training dataset.
def compute_cosine_distance_matrix(feat, feat_matrix):cosine_dist_matrix = scipy.spatial.distance.cdist(feat_matrix, feat.reshape(1, -1), 'cosine').reshape(-1, 1)return 1 - cosine_dist_matrix
I experimented with using various maxpool layers from VGG to extract features for similarity calculations and found that early and later layers performed best in identifying images that looked similar on visual inspection. I created a demo that shows the top 24 most similar images from the dataset for each generated image based on features from two layers in a VGG network - an early layer and a later layer (block5_pool).
An interface that displays images similar to the generated images from the GAN. Similarity is computed as cosine distance of features extracted from layers of a pretrained CNN (VGG). Qualitative inspection suggests using an features from an early layer (block1_pool) finds images with similar low level features (color, pixels, texture), while later layers find images with similar high level features (shapes and and objects) etc. Check out the demo on this here
Initial results show the GAN is generating images that are fairly distinct from their closest relatives in the dataset. There were no obvious copies. This interpretation is subjective, limited by the blurry nature of the generated images and the reader is encouraged to view the demo to form a better opinion.
The interactive examination of the generated images also provides opportunity to view some interesting modes within the dataset. Some include masks with certain sideways orientations, masks with hair or hair-like projections, oblong masks. Similarity information can also be a (weakly supervised) technique for curating image datasets, enabling specific "modes" of the dataset and finding outliers aka bad images.

Summary
- Working with TPUs was easier than I originally imagined. The Estimator API is very well designed (encapsulated the training loop); existing Estimator API code was read and follow. For individuals already familiar with estimators (or other framework that support a standardized training NN training loop), it would be easy getting work done.
- One of the troublesome parts during this project was troubleshooting my data conversion script (from raw images, to TFrecords which are ingested during training). I had extended the sample DCGAN code which happens to expect an image tensor in the shape [channel, height, width] instead of [height, width, channel] which I was more used to. This did not throw any error - it just meant the first 30 or so experiments I ran generated absolutely noisy nonsense. TFrecords are excellent for many reasons - however, it would be useful is Tensorflow could better standardize this process (not sure if TF already has something close to torchvision imageFolder).
- Assembling a clean dataset is quite an important part of actually using GANs for meaningful artistic explorations. This makes a case for tools that support the curation of datasets - possibly in a semi-supervised manner where we label a small sample, train a model on this sample and use it to "curate" the rest of the data.
- GANs can be useful for artistic exploration. In this case, while some of the generated images are not complete masks, they excel at capturing the texture or feel of African art. For example, I showed a colleague and they mentioned the generated images had a "tribal feel to it".
- Much of existing work in the area of GANs focus on generating "realistic" images. While this is incredibly useful (infact, this is desirable for applications such as GANs for super resolution), its also important to understand how much information from the training data is incorporated,* how they are combined *in generating new images, and if these images are really novel. Qualitative inspection experiments (real world datasets) can provide insights in this areas.
- Pre-trained models work well as feature extractors for these inspection/similarity experiments (as opposed to simple L1 distances in pixels - Karras et al 2017 [2]). Early layers allow us examine similarity based on low level features such as lines and textures, while later layers focus on high level features such as shapes.
Bonus - Two Stage Generation.
64px images can be further upsampled to higher resolutions using Super Resolution GANs. Some results shown below from experiments using the Topaz Labs Gigapixel model

Next Steps
I definitely learned a bit about GANs while working on this project; Many thanks to Google for making TPUs available. As always, there are numerous opportunities for future work. Some of the ones I am considering include - extending the Africa Masks dataset, experiments with conditioned GANs (how might the features learned correspond to artistic properties?) and other architectures for realistic/higher resolution image generation.
Got ideas for what to do next? Feel free to reach out on Twitter, Github or Linkedin.
References
[1] A. Radford, L. Metz, and S. Chintala, "Unsupervised representation learning with deep convolutional generative adversarial networks," arXiv1511.06434 [cs], pp. 1--16, 2016.
[2] T. Karras, T. Aila, S. Laine, and J. Lehtinen, "Progressive Growing of GANs for Improved Quality, Stability, and Variation," CoRR, vol. abs/1710.1, Oct. 2017.
 Signature Image Cleaning with Tensorflow 2.0 - TF.Data and Autoencoders
Signature Image Cleaning with Tensorflow 2.0 - TF.Data and Autoencoders Introducing Peacasso: A UI Interface for Generating AI Art with Latent Diffusion Models (Stable Diffusion)
Introducing Peacasso: A UI Interface for Generating AI Art with Latent Diffusion Models (Stable Diffusion) How to Speed Up Neural Network Training with Intel's Gaudi HPUs. A Tensorflow 2.0 Object Detection Example
How to Speed Up Neural Network Training with Intel's Gaudi HPUs. A Tensorflow 2.0 Object Detection Example State of Deep Learning for Object Detection - You Should Consider CenterNets!
State of Deep Learning for Object Detection - You Should Consider CenterNets! Recent Breakthroughs in AI (Karpathy, Johnson et al, Feb 2021)
Recent Breakthroughs in AI (Karpathy, Johnson et al, Feb 2021) 2018 Year in Review
2018 Year in Review Latent Diffusion Models: Components and Denoising Steps
Latent Diffusion Models: Components and Denoising Steps