State of Deep Learning for Object Detection - You Should Consider CenterNets!
This post presents a short discussion of recent progress in practical deep learning models for object detection.
Source: Tensorflow Object Detection API , Ultralytics
I explored object detection models in detail about 3 years ago while builidng Handtrack.js and since that time, quite a bit has changed. For one, MobileNet SSD[^2] was the gold standard for low latency applications (e.g. browser deployment), now CenterNets[^1] appear to do even better.
This post does not pretend to be exhaustive, but focuses on methods that are practical (reproducible checkpoints exist) for today's usecases. Hence the excitement for CenterNets[^1]! The reader is encouraged to review papers listed in the references section below for more indepth discussions.
I also highly recommend the Tensorflow Object detection api[^3] from Google as a source of reference implementations; this post visualizes the performance metrics of pretrained models which they report and metrics from Ultralytics on Yolov5[^7].
TLDR;
Benchmarking Data Source
The data used in the chart above is harvested from the Tensorflow Object detection model zoo[^1]. Based on this Github issue[^4], the timings reported are based on experiments with an Nvidia GeForce GTX TITAN X card.
Data on Yolov5 is also added from the Ultralytics Benchmarks[^7] which is conducted on a Tesla v100 GPU and uses a PyTorch implementation. To compare FPS, I generously assume a Tesla v100 is 1.6x faster than a Titan X based on comparisons in this Lambdalabs GPU benchmarking article[^6].
Object Detection Primer
The task of Object detection is focused on predicting the where and what each object instance. For instance, given an image of a breakfast table, we want to know where the objects of interest (plates, forks, knives, cups) are located (bounding box cordinates). Models that achieve this goal must solve two tasks - first, they must identify regions within an image that contain objects (region proposal), and then they must classify these regions into 1 of n categories. To perform the second task, you typically need to incoporate a model that can understand images well e.g. a pretrained image classification model (e.g. ResNet50, EfficientNet, Stacked HourGlassNets trained on the ImageNet dataset). This pretrained model, called a backbone, is then used in some section of the object detection model to extract feature maps that help in predicting things like if an object exists in a section of the image, the class of this object and its location.
Research in this area hag gone through several generations of iterations:
Two Stage Detection
Two stage object detection models typically have two distinct parts. The first stage focuses on generating proposals (i.e. what parts of my image are likely to contain objects?). This may be done using a region proposal algorithm like selective search [^13] (e.g. as seen in RCNN) or with a region proposal network - RPN which takes in feature map produced by a backbone network, and predicts regions where an object exists (e.g. as seen in Fast R-CNN, Mask R-CNN, Cascade R-CNN, CPNs [^11] etc).
Early RPNs used the concept of anchor boxes - a set of k predefined boxes at different aspect ratios and scales to predict if a section of a feature map (from backbone) contains an object. RPNs also predict refinements where needed that tranform the initial anchor box to match a proposal box.
The second stage takes proposed regions, and predicts object class and any additional refinements or bounding box offsets. Note that RPNs may be implemented using multiple approaches e.g recent two stage models like CPNs do not use anchor boxes in their RPN.
Single Stage Detection
This gets rid of the first stage and explores how the same network can be used to predict both the presence of objects, class of object and region/bbox transforms/offsets.
-
Anchor based detectors: Models in this category leverage the concept of anchor boxes described above. We slide each anchor box across the preceeding feature map and predict if an object exists + any refinements. Examples include RetinaNet[^12], SSD[^9], YOLO, and Faster R-CNN. Anchor based detectors rely on a set of anchor boxes of fixed size (a hyperparameter that needs to be tuned carefully), making it hard to detect objects that dont fit well within the selected anchor box shapes. In addition class predictions and refinements for each box incure compute cost.
-
Anchor free detectors: More recently, there have been efforts to simplify single stage detectors by removing the need for a predefined set of anchor boxes and the computational costs they incur (sliding them across feature maps). Examples of this approach include CenterNets[^1] (more below), ConerNets[^10], FCOS[^8].
Two-stage detectors are often more accurate but slower, compared to one-stage detectors.
Why Do CenterNets (and Anchor Free Models) Work So Well?
So - why do CenterNets[^1] (and related anchor free models) appear to work so well in terms of achieving decent perfomance at lower latency? The short answer is that they reformulate the object detection task from generating and classifying proposals into a simpler problem - predicting objects’ centers (keypoints) and regress their corresponding attributes (width and height). This (anchor free) formulation provides a few benefits:
- Avoids the use of anchor boxes (fixed number of prototypical boxes that we slide over the image at multiple scales) which can be costly to compute (quadratic to pixels).
- More amenable (in theory) to oddly shaped objects which an anchor box method might miss.
- Avoids the need for non maxima suppression (since we dont have these anchor boxes which generate duplicate detections).
CenterNets have also been applied to adjacent tasks such as (Multi) Object Tracking, Segmentation, Movement prediction etc [^5].
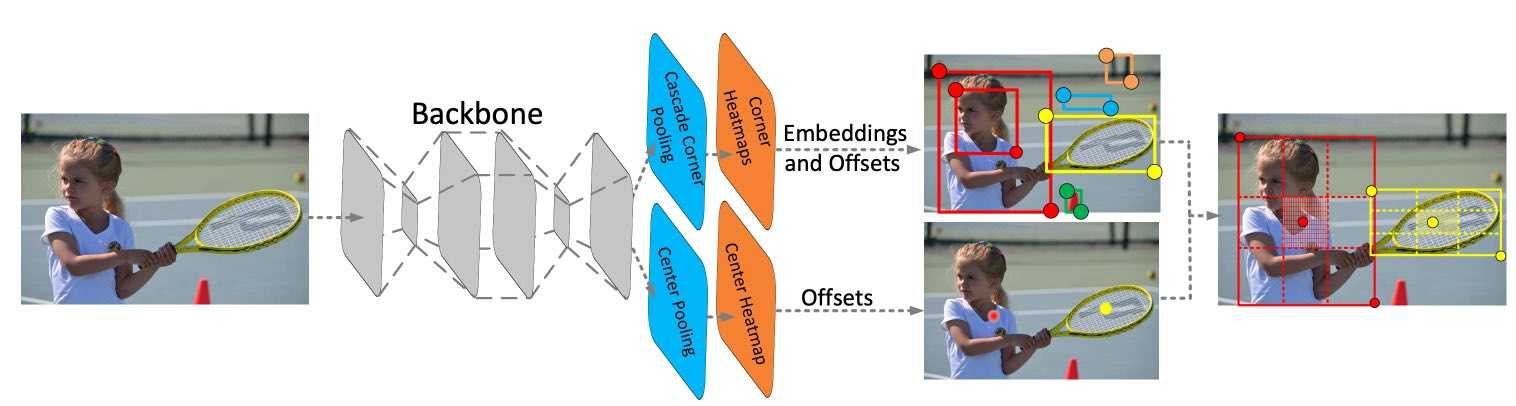
I certainly look forward to digging in and experimenting with CenterNets.
References
[^1]: Duan, Kaiwen, et al. "Centernet: Keypoint triplets for object detection." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019. [^2]: Liu, Wei, et al. "Ssd: Single shot multibox detector." European conference on computer vision. Springer, Cham, 2016. [^3]: Tensorflow 2.0 Object Detection API model zoo. https://github.com/tensorflow/models/blob/master/research/object_detection/ [^4]: Tensorflow Object Detection API Performance Issue https://github.com/tensorflow/models/issues/3243 [^5]: CenterNet and its variants http://guanghan.info/blog/en/my-thoughts/centernet-and-its-variants/ [^6]: Titan RTX Deep Learning Benchmarks https://lambdalabs.com/blog/titan-rtx-tensorflow-benchmarks/ [^7]: Ultralytics Yolov5 Benchmarks https://github.com/ultralytics/yolov5 [^8]: Tian, Zhi, et al. "Fcos: A simple and strong anchor-free object detector." IEEE Transactions on Pattern Analysis and Machine Intelligence (2020). [^9]: Liu, Wei, et al. "Ssd: Single shot multibox detector." European conference on computer vision. Springer, Cham, 2016. [^10]: Law, Hei, and Jia Deng. "Cornernet: Detecting objects as paired keypoints." Proceedings of the European conference on computer vision (ECCV). 2018. [^11]: (CPN) Duan, Kaiwen, et al. "Corner proposal network for anchor-free, two-stage object detection." arXiv preprint arXiv:2007.13816 (2020). [^12]: Lin, Tsung-Yi, et al. "Focal loss for dense object detection." Proceedings of the IEEE international conference on computer vision. 2017. [^13]: OpenCV Selective Search for Object Detection https://www.pyimagesearch.com/2020/06/29/opencv-selective-search-for-object-detection/
 U2Net Going Deeper with Nested U-Structure for Salient Object Detection | Paper Review
U2Net Going Deeper with Nested U-Structure for Salient Object Detection | Paper Review How to Speed Up Neural Network Training with Intel's Gaudi HPUs. A Tensorflow 2.0 Object Detection Example
How to Speed Up Neural Network Training with Intel's Gaudi HPUs. A Tensorflow 2.0 Object Detection Example Top 10 Machine Learning and Design Insights from Google IO 2021
Top 10 Machine Learning and Design Insights from Google IO 2021 Recent Breakthroughs in AI (Karpathy, Johnson et al, Feb 2021)
Recent Breakthroughs in AI (Karpathy, Johnson et al, Feb 2021) ART + AI — Generating African Masks using (Tensorflow and TPUs)
ART + AI — Generating African Masks using (Tensorflow and TPUs) Signature Image Cleaning with Tensorflow 2.0 - TF.Data and Autoencoders
Signature Image Cleaning with Tensorflow 2.0 - TF.Data and Autoencoders