How to Finetune BERT for Text Classification (HuggingFace Transformers, Tensorflow 2.0) on a Custom Dataset

The huggingface transformers library makes it really easy to work with all things nlp, with text classification being perhaps the most common task. The libary began with a Pytorch focus but has now evolved to support both Tensorflow and JAX!
I recently ran some experiments to train a model (more like fine tune a pretrained model) to classify tweets as containing politics related content or not. The goal was to train the model on a relatively large dataset (~7 million rows), use the resulting model to annotate a dataset of 9 million tweets, all of this being done on moderate sized compute (single P100 gpu). I used the huggingface transformers library, using the Tensorflow 2.0 Keras based models.
TLDR;
- Training:
- Shuffle and chunk large datasets smaller splits (bad things happen if you forget to shuffle ... e.g., a split containing a single label).
- Tokenize text for each split and construct a
tf.dataobject. - Iteratively train model on each split. (.. reserve last split for evaluation as needed).
- Prediction:
- Chunk data into splits
- Apply batching optimizations to speed up prediction on each split. Construct batches based on text sorted by length, such that similar sized text are in the same batch.
- Predict on batches and aggregate results.
A related text classification example from the HuggingFace team can be found here [^1] (there isn't much detail on how to train on custom data or data that does not fit in memory, which is what this post focuses on).
Why HuggingFace and Tensorflow ?
In theory you could use other pretrained models (e.g., the excellent models from TF Hub) or frameworks, or AutoML tools (e.g., GCP Vertex AI automl for text). However, there are several reasosn why HuggingFace and Tensorflow were a good fit for my project:
- HF is supports a broad set of pretrained models and lots of well designed tools and methods. E.g., their fast tokenizer, model loading and saving scripts work really well.
- HF supports Tensorflow 2.0 (keras) based model and training abstractions which is something I am familiar with.
- Control over costs and model. Having control over the model and training loop (as opposed to something like automl) is overall more cost effective. Having access to the underlying keras model (e.g., vs automl) provides a change to build interesting things like explainability probes (e.g., what tokens drive the prediction?).
Dataset and Problem (Political Text Classification)
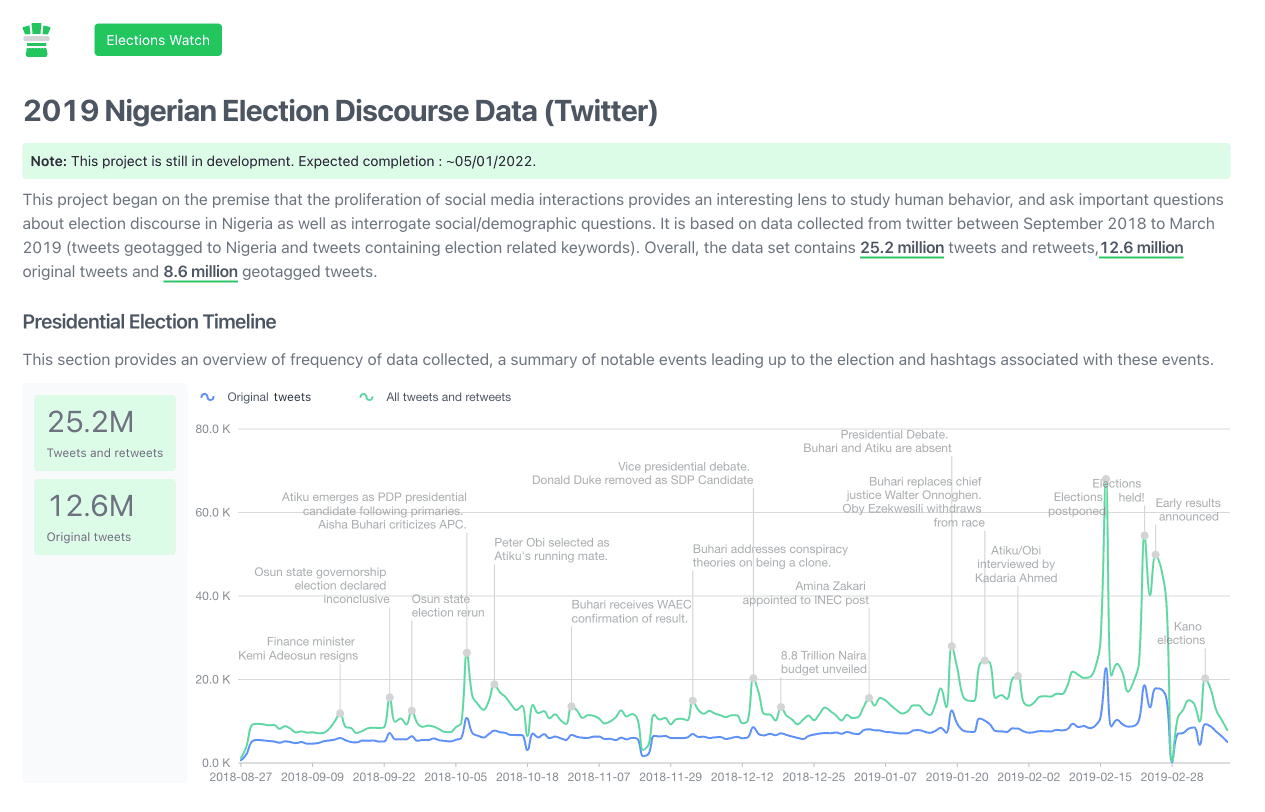
A while ago, I was interested in studying election discourse and citizen participation in Nigeria. As part of that I collected tweets (12.6 million original tweets) spanning the period of 6 months during the 2019 Nigerian presidential elections. I built an interactive visualization of some insights from the data here.
One primary task was to identify which of the tweets were explicitly discussing politics and analyze them further. As a first step, I assembled a list of election related keywords relevant to the dataset (e.g., candidate names, party names, etc) and used that to select a subset of politics related tweets. I then sampled an equal amount of non politics related tweets resulted in a 4 million row dataset used in training. This is an example of how simple heuristics can be used to assemble an initial dataset for training a baseline model. Note that a main limitation of the resulting model is that it will be unable to identify non-political text that contain political keywords.
I plan to release a subset of this dataset at some point. Until then, this kaggle dataset can be used to train a similar model.
From DataFrame to Tensorflow Dataset
Assuming we have a dataframe with two columns - text and label , we can use the following steps to create a tf.data.Dataset object that is used to train a keras model.
Split dataframe into train and test.
from transformers import AutoModelForSequenceClassification, TFAutoModelForSequenceClassification,TFBertForSequenceClassificationfrom transformers import AutoTokenizerimport tensorflow as tfimport numpy as npfrom sklearn.model_selection import train_test_splitfrom transformers import BertTokenizerFasttokenizer = BertTokenizerFast.from_pretrained('bert-base-cased')
Create tensorflow datasets from the tokenized data. (See this similar example from the HuggingFace docs [^3].)
def get_train_ds(data_path, batch_size=32):data = pd.read_hdf(data_path)data = data.sample(n=300000) # optionally sample a subset of the dataX_train, y_train = list(data.text), list(data.label)train_encodings = tokenizer(X_train, truncation=True, padding=True)train_ds = tf.data.Dataset.from_tensor_slices((dict(train_encodings),y_train))train_ds = train_ds.batch(batch_size)return train_ds
Note on the tf.data.Dataset Pipeline for Large Datasets
In the code above, we first tokenize the text and then convert it to a tf.data dataset using from_tensor_slices which is held in memory. For really large datasets, this would lead to an OOM error. An alternative will be to create a tf.data dataset based on raw text and labels (smaller than tokenized representation of text), and apply a map function which tokenizes batches of text on the fly. The one challenge I faced while attempting to implement this is that the huggingface pretrained model requires a dictionary as input ({"input_ids": [..], "attention_mask": [..]}) and so care needs to be taken to generate batches that match this exact contract.
I explored the tf.py_function approach which wraps a python function as a tensorflow op that can be executed eagerly (described here[^4]) but could not particularly get the right results. My manual inspection indicates the dataset is constructed correctly, but training still fails. See implementation and error below. Will update this section once I get additional insights).
train_ds = tf.data.Dataset.from_tensor_slices((X_train, y_train)).batch(2)def py_func(x):x = x.numpy()x = [i.decode("utf-8") for i in x]d = tokenizer(x, truncation=True, padding=True)return list(d.values())def ds_map_fn(x,y):flattened_output = tf.py_function(py_func, [x], [tf.int32, tf.int32])return {"input_ids": flattened_output[0], "attention_mask": flattened_output[1]},ytrain_ds = train_ds.map(ds_map_fn)for x,y in train_ds.take(2):print(x)## But I still get an error# OperatorNotAllowedInGraphError: iterating over `tf.Tensor`# is not allowed: AutoGraph did convert this function.# This might indicate you are trying to use an unsupported feature.
As an alternative, what I have done for larger datasets is to first shuffle my data (to ensure similar distribution of data across splits), and split into several slices. Next, I load each split in memory, tokenize and construct a tf.data dataset, train the model and save to disc. Then repeat this process, incrementally training the same model on all splits.
Train and Save the Model
model = TFBertForSequenceClassification.from_pretrained("bert-base-cased", num_labels=2 )lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(initial_learning_rate=5e-5,decay_steps=10000,decay_rate=0.9)optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)model.compile(optimizer=optimizer,loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=tf.metrics.SparseCategoricalAccuracy()) # can also use any keras loss fn
Write a method to incrementally call model.fit on a train data slice and save both the tokenizer and model to disc.
def train_on_slice(train_ds):model.fit(train_ds, epochs=1)tokenizer.save_pretrained(f"{out_model_path}")model.save_pretrained(f"{out_model_path}")for file_name in tqdm(file_list):train_ds = get_train_ds(f"{file_name}")train_on_slice(train_ds)
Load Model and Make Predictions
Now we have a trained model, the next task is to .. well use it to make predictions. In my case, I wanted to be as efficient as possible, given I wanted to predict on a 9 million row dataset. I explored prediction using the huggingface pipeline api and then writing my own batched custom prediction pipeline.
Loading a Saved Model
We can load both the tokenizer and model using the from_pretrained method.
from transformers import BertTokenizerFast,TFBertForSequenceClassificationimport numpy as npimport tensorflow as tffrom transformers import TextClassificationPipelinemodel_path = "..."tokenizer = BertTokenizerFast.from_pretrained(model_path)model = TFBertForSequenceClassification.from_pretrained(model_path, id2label={0: 'general', 1: 'political'} ) # modify labels as needed.
Prediction with HuggingFace Pipelines
We can use the huggingface pipeline[^2] api to make predictions. The advantage here is that is is dead easy to implement.
text = ["The results of the elections appear to favour candidate obasangjo","The sky is green and beautiful","Who will win? inec will decide"]pipe = TextClassificationPipeline(model=model, tokenizer=tokenizer)pipe(text)
Output
[{'label': 'political', 'score': 0.999734103679657},{'label': 'general', 'score': 0.9929350018501282},{'label': 'political', 'score': 0.9998018145561218}]
One thing I noticed was that, by default, batching is not enabled for pipelines, and which can be quite slow (a forward pass for each item). Also, the impact of batching can be influenced by the composition of the batch; token length for the batch is token length for the longest text in the batch.
Custom Prediction Pipeline
Given my goal was to run prediction on 9 million rows of text with limited compute, optimization speedups were important. I did the following:
- Split data into chunks (mostly just enough to fit in memory)
- Sort data based on text length - this is important as it allows similar sized text to fall within the same batch.
- Tokenize data and construct a
tf.dataobject and apply batching - Run predictions. Predictions for the first few batches with the smallest text lengths run pretty fast. In my experiments, sorting resulted in about 25% speedup on a small slice of data.
def extract_predictions(text, batch_size=64):a_preds = []a_scores = []chunks = range(0,len(text), batch_size)for i,x, in tqdm(enumerate(chunks), total=len(chunks)):start, end = x, x+batch_sizestext = text[start: end]data_encodings = tokenizer(stext, truncation=True, padding=True)ds = tf.data.Dataset.from_tensor_slices(dict(data_encodings)).batch(batch_size)preds = model.predict(ds)["logits"]classes = np.argmax(preds, axis=1).tolist()probs = tf.nn.softmax(preds) # get probabilities from logitsscores = np.amax(probs, axis=1).tolist()a_preds.extend(classes)a_scores.extend(scores)# return predictions and scoresans = []for i in range(len(a_preds)): # map labels to label titlesans.append({"label": "general" if a_preds[i] == 0 else "political","score": a_scores[i]})ansdf = pd.DataFrame(ans)return ansdfresult = extract_predictions(text, batch_size=256)
Miscellaneuous: Stuff That Did/Could go Wrong
While training this model, there are a few simple gotchas that can turn out to be annoying time wasters. Some of the things that got me along the way:
-
Data tests: It is always a good idea to perform a series of manual checks on your data just before training. In my case, while tinkering with my data preprocessing script (chunking tweets into smaller files), one edit (to a notebook) failed to shuffle data before chunking (result being that a few batches had data from a single class! 😬😬). A simple data test would have caught this issue.
-
Data storage format: I initially stored my training data slices in
.csvfiles. Big mistake. Turns out that at some random points during training,pd.read_csvled to random decoding errors and empty batches. In my case, tweets may contain special characters which might need specific encoding (pd.read_csvhas an encoding parameter). While there are many other great formats, in my case, a simple switch tohd5format solved this issue. -
Learning rate schedule. I had a relatively large dataset to train on (~7M rows). Not using a learning schedule meant that after a few 1000 steps, the model loss started to increase and accuracy decreased (see this article on setting learning rate.[^5]). Applying a learning schedule with exponential decay helps to mitigate this. Keras ExponentialDecay api makes this easy to implement. There have also been other notes that discuss training instability associated with finetuning a pretrained BERT model.
-
Defensive training loops: Several things can go wrong, expecially when you write your own training loop. A common issue has to do with memory. For text models, the amount of memory allocations for each training pass depends on the size of the largest text in the batch. You can set a max_token_length to limit this and ensure your batch can fit in your machine memory. Other useful tips include saving the model at intervals, to allows for resuming training in the event of failures.
-
Infrastructure: I typically use Colab for small projects like this. However, with the size of my dataset, training took about 11 hours. I setup a GCP GPU backend for Colab to ensure there were no timeouts.
In addition to the above, check out the list of steps suggested by Andrej Karpathy in his blog post - A recipe for training neural networks.
Conclusion
The Huggingface library is quite handy! Note that you can switch to any of the huggingface models (there are 100s) and use about the same code.
References
[^1]: Text classification with HuggingFace https://huggingface.co/docs/transformers/tasks/sequence_classification [^2]: Huggingface Pipelines https://huggingface.co/docs/transformers/main_classes/pipelines [^3]: Huggingface Transformers | Fine-tuning with custom datasets https://huggingface.co/transformers/v4.0.1/custom_datasets.html [^4]: Tensorflow Github Issue - tf.py_function could return a dictionary of tensors https://github.com/tensorflow/tensorflow/issues/38212 [^5]: Setting the learning rate of your neural network https://www.jeremyjordan.me/nn-learning-rate/
 How to Implement Extractive Summarization with BERT in Pytorch
How to Implement Extractive Summarization with BERT in Pytorch How to Implement Gradient Explanations for a HuggingFace Text Classification Model (Tensorflow 2.0)
How to Implement Gradient Explanations for a HuggingFace Text Classification Model (Tensorflow 2.0) Signature Image Cleaning with Tensorflow 2.0 - TF.Data and Autoencoders
Signature Image Cleaning with Tensorflow 2.0 - TF.Data and Autoencoders How to Build MultiModal Recommender Systems with Tensorflow
How to Build MultiModal Recommender Systems with Tensorflow How to Build An Android App and Integrate Tensorflow ML Models
How to Build An Android App and Integrate Tensorflow ML Models ART + AI — Generating African Masks using (Tensorflow and TPUs)
ART + AI — Generating African Masks using (Tensorflow and TPUs)