How to Build MultiModal Recommender Systems with Tensorflow
Recommender systems are everywhere! On Tiktok, they suggest the next viral clip; On Youtube, the next interesting video; On Twitter, they compile the list of tweets we wee on our feed. In many ways, these algorithms determine what we get to see or not see! But how do they work and how can we build these sort of systems? While recommender systems are complex and can be implemented in multiple different ways, each approach must do a few things. First, it must derive some representation of the problem context (e.g., who is the user and what are their preference), next it must compute some measure of relevance (i.e., how can I tell if an item is suitable to the given context?) and it must provide results that maximize relevance.
In this post, we will walk through the hypothetical use case of building TweetMaker - a tool that recommends images that you can add to your tweet to make it more engaging! We will discuss the process across the following
- Problem framing. How do we translate the task to a machine learning problem?
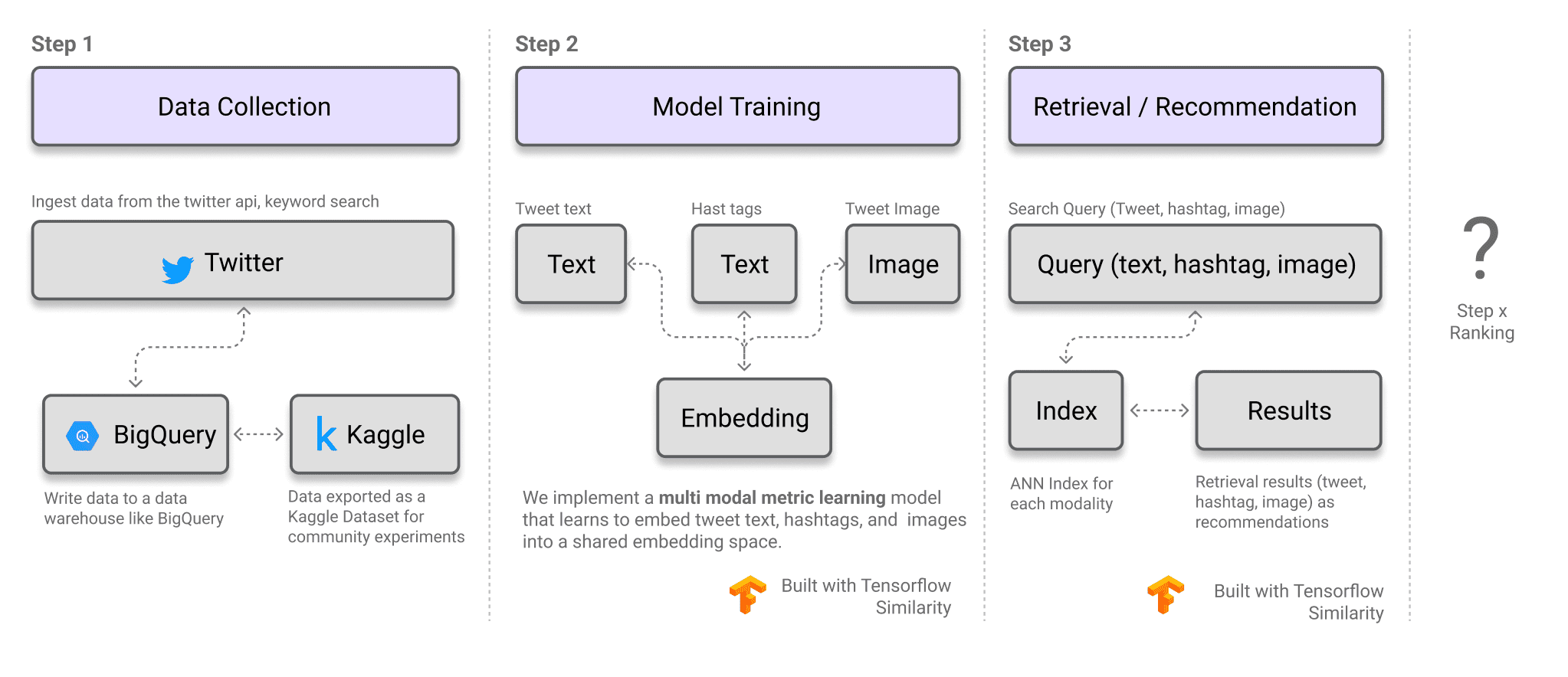
- Data Collection. What data pairs and data fields do we need? Walkthrough on collecting sample data from twitter and ingesting it into BigQuery
- Model Training. How do we train the underlying ML models e.g., a multimodal similarity model built with Tensorflow Similarity
- Model Evaluation. How do we evaluate the model to ensure it is fit for purpose?
Notebook and Code Structure
Full Notebook and code is available on Kaggle - https://www.kaggle.com/code/victordibia/multimodal-metric-learning-tensorflow-similarity
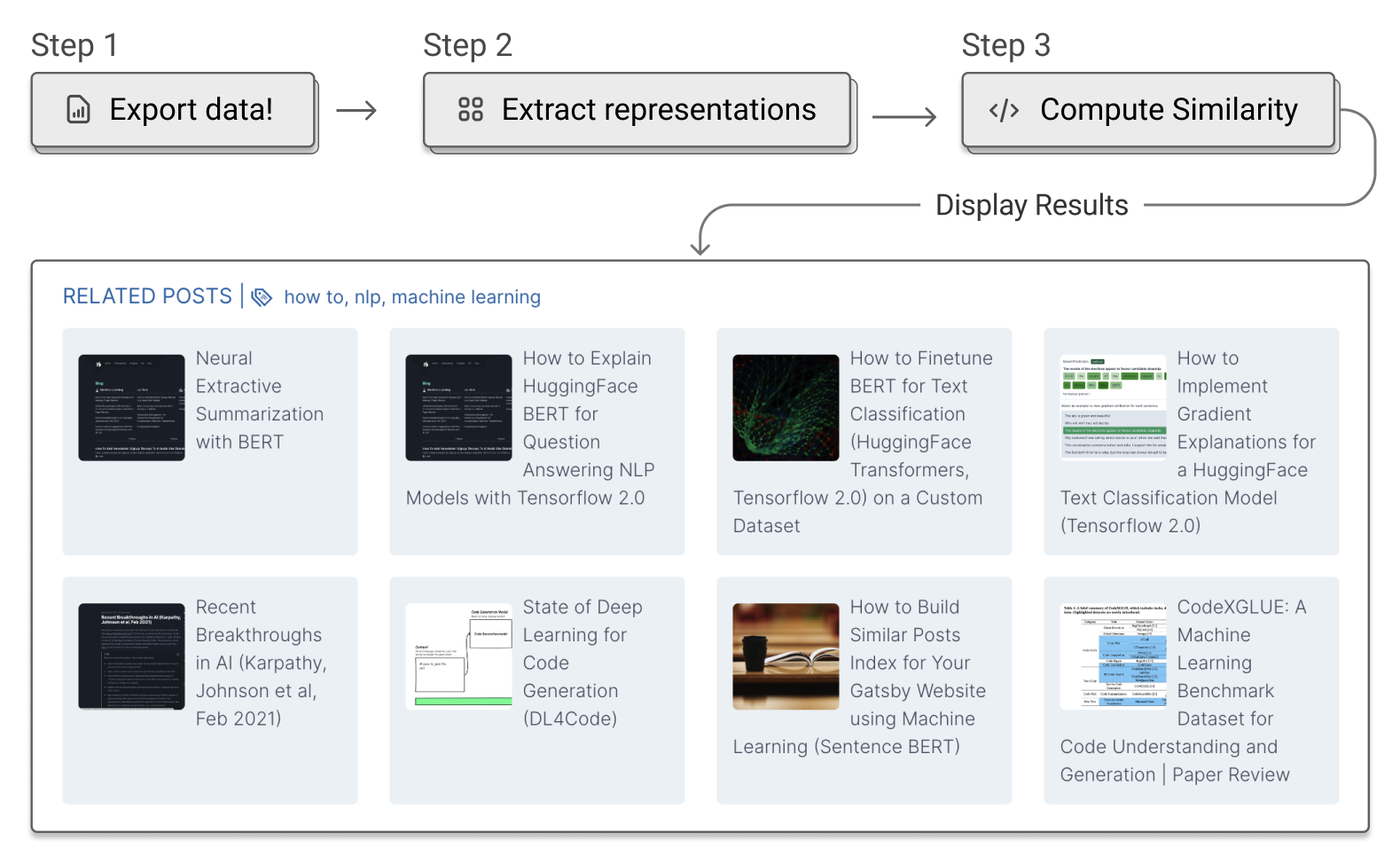 How to Build a Similar Posts Feature for Your Gatsby (JAMSTACK) Website using Machine Learning (Document Similarity)
How to Build a Similar Posts Feature for Your Gatsby (JAMSTACK) Website using Machine Learning (Document Similarity) Introducing Peacasso: A UI Interface for Generating AI Art with Latent Diffusion Models (Stable Diffusion)
Introducing Peacasso: A UI Interface for Generating AI Art with Latent Diffusion Models (Stable Diffusion) Top 10 Machine Learning and Design Insights from Google IO 2021
Top 10 Machine Learning and Design Insights from Google IO 2021 How to Finetune BERT for Text Classification (HuggingFace Transformers, Tensorflow 2.0) on a Custom Dataset
How to Finetune BERT for Text Classification (HuggingFace Transformers, Tensorflow 2.0) on a Custom Dataset Recent Breakthroughs in AI (Karpathy, Johnson et al, Feb 2021)
Recent Breakthroughs in AI (Karpathy, Johnson et al, Feb 2021) How to Implement Gradient Explanations for a HuggingFace Text Classification Model (Tensorflow 2.0)
How to Implement Gradient Explanations for a HuggingFace Text Classification Model (Tensorflow 2.0) How to Implement Extractive Summarization with BERT in Pytorch
How to Implement Extractive Summarization with BERT in Pytorch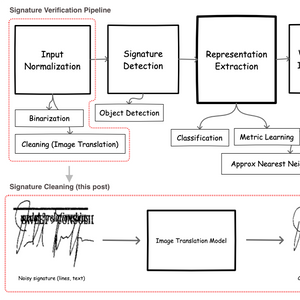 Signature Image Cleaning with Tensorflow 2.0 - TF.Data and Autoencoders
Signature Image Cleaning with Tensorflow 2.0 - TF.Data and Autoencoders