How to Implement Extractive Summarization with BERT in Pytorch
In a previous post, we discussed how extractive summarization can be framed as a sentence classification problem. In this post we will explore an implementation of a baseline model starting with data preprocessing, model training/export and inference using Pytorch and the HuggingFace transformers library.
Model Architecture
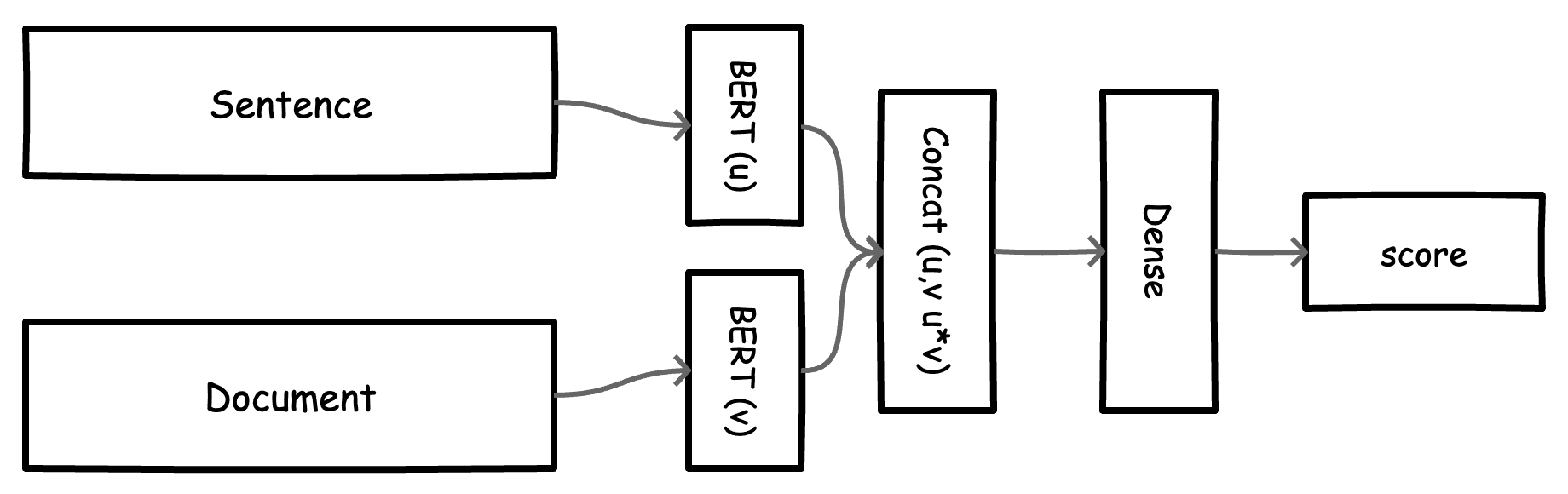
The model takes in a pair of inputs X=(sentence, document) and predicts a relevance score y. We need representations for our text input. For this, we can use any of the language models from the HuggingFace transformers library. Here we will use the sentence-transformers where a BERT based model has been finetuned for the task of extracting semantically meaningful sentence embeddings.
from transformers import AutoTokenizer, AutoModelsentence_model_name = "sentence-transformers/paraphrase-MiniLM-L3-v2"tokenizer = AutoTokenizer.from_pretrained(sentence_model_name)# get mean pooling for sentence bert models# ref https://www.sbert.net/examples/applications/computing-embeddings/README.html#sentence-embeddings-with-transformersdef mean_pooling(model_output, attention_mask):token_embeddings = model_output[0] #First element of model_output contains all token embeddingsinput_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1)sum_mask = torch.clamp(input_mask_expanded.sum(1), min=1e-9)return sum_embeddings / sum_maskclass SentenceBertClass(torch.nn.Module):def __init__(self, model_name="sentence-transformers/paraphrase-MiniLM-L3-v2", in_features=384):super(SentenceBertClass, self).__init__()self.l1 = AutoModel.from_pretrained(model_name)self.pre_classifier = torch.nn.Linear(in_features*3, 768)self.dropout = torch.nn.Dropout(0.3)self.classifier = torch.nn.Linear(768, 1)self.classifierSigmoid = torch.nn.Sigmoid()def forward(self, sent_ids, doc_ids, sent_mask, doc_mask):sent_output = self.l1(input_ids=sent_ids, attention_mask=sent_mask)sentence_embeddings = mean_pooling(sent_output, sent_mask)doc_output = self.l1(input_ids=doc_ids, attention_mask=doc_mask)doc_embeddings = mean_pooling(doc_output, doc_mask)# elementwise product of sentence embs and doc embscombined_features = sentence_embeddings * doc_embeddings# Concatenate input features and their elementwise productconcat_features = torch.cat((sentence_embeddings, doc_embeddings, combined_features), dim=1)pooler = self.pre_classifier(concat_features)pooler = torch.nn.ReLU()(pooler)pooler = self.dropout(pooler)output = self.classifier(pooler)output = self.classifierSigmoid(output)return output
Model Training
Next, we instantiate the model, move it to a GPU is available and specify training parameters (learning rate, and binary cross entropy loss).
from torch import cudadevice = 'cuda' if cuda.is_available() else 'cpu'model = SentenceBertClass(model_name=sentence_model_name)model.to(device)loss_function = torch.nn.BCELoss()optimizer = torch.optim.Adam(params = model.parameters(), lr=LEARNING_RATE)
Next, we specify the model training loop. For each batch of data from our data loader, we first tokenize the input text, get predictions, compute gradients and update model weights. We also keep a running sum of performance metrics per batch for subsequent visualization.
def train(epoch):tr_loss = 0n_correct = 0nb_tr_steps = 0nb_tr_examples = 0model.train()for _,data in tqdm(enumerate(training_loader, 0)):sent_ids = data['sent_ids'].to(device, dtype = torch.long)doc_ids = data['doc_ids'].to(device, dtype = torch.long)sent_mask = data['sent_mask'].to(device, dtype = torch.long)doc_mask = data['doc_mask'].to(device, dtype = torch.long)targets = data['targets'].to(device, dtype = torch.float)outputs = model(sent_ids, doc_ids, sent_mask, doc_mask)loss = loss_function(outputs, targets)tr_loss += loss.item()n_correct += torch.count_nonzero(targets == (outputs > 0.5)).item()nb_tr_steps += 1nb_tr_examples+=targets.size(0)if _%print_n_steps==0:loss_step = tr_loss/nb_tr_stepsaccu_step = (n_correct*100)/nb_tr_examplesprint(str(_* train_params["batch_size"]) + "/" + str(len(train_df)) + " - Steps. Acc ->", accu_step, "Loss ->", loss_step)acc_step_holder.append(accu_step), loss_step_holder.append(loss_step)optimizer.zero_grad()loss.backward()# # When using GPUoptimizer.step()print(f'The Total Accuracy for Epoch {epoch}: {(n_correct*100)/nb_tr_examples}')epoch_loss = tr_loss/nb_tr_stepsepoch_accu = (n_correct*100)/nb_tr_examplesprint(f"Training Loss Epoch: {epoch_loss}")print(f"Training Accuracy Epoch: {epoch_accu}")returnfor epoch in range(EPOCHS):train(epoch)
Model Evaluation
To evaluate the model, we can write a loop similar to our training loop where we get predictions for data in each batch of our test set but do not update model weights.
def validate_model(model, testing_loader):model.eval()n_correct = 0; n_wrong = 0; total = 0; tr_loss = 0; nb_tr_steps = 0 ; nb_tr_examples = 0with torch.no_grad():for _, data in enumerate(testing_loader, 0):sent_ids = data['sent_ids'].to(device, dtype = torch.long)doc_ids = data['doc_ids'].to(device, dtype = torch.long)sent_mask = data['sent_mask'].to(device, dtype = torch.long)doc_mask = data['doc_mask'].to(device, dtype = torch.long)targets = data['targets'].to(device, dtype = torch.float)outputs = model(sent_ids, doc_ids, sent_mask, doc_mask)loss = loss_function(outputs, targets)tr_loss += loss.item()n_correct += torch.count_nonzero(targets == (outputs > 0.5)).item()nb_tr_steps += 1nb_tr_examples+=targets.size(0)if _%print_n_steps==0:loss_step = tr_loss/nb_tr_stepsaccu_step = (n_correct*100)/nb_tr_examplesprint(str(_* test_params["batch_size"]) + "/" + str(len(train_df)) + " - Steps. Acc ->", accu_step, "Loss ->", loss_step)epoch_loss = tr_loss/nb_tr_stepsepoch_accu = (n_correct*100)/nb_tr_examplesprint(f"Validation Loss Epoch: {epoch_loss}")print(f"Validation Accuracy Epoch: {epoch_accu}")return epoch_accu
Model Inference
Inference is implemented in the summarize method in the snippet below.
First we sentencify our document (break up the document into individual sentences using a spacy language model), get score predictions for each sentence, sort by score and order of appearance and then return the top_k sentences as the summary.
# create spacy modelnlp = spacy.load('en_core_web_lg')# tokenize text as required by BERT based modelsdef get_tokens(text, tokenizer):inputs = tokenizer.batch_encode_plus(text,add_special_tokens=True,max_length=512,padding="max_length",return_token_type_ids=True,truncation=True)ids = inputs['input_ids']mask = inputs['attention_mask']return ids, mask# get predictions given some an array of sentences and their corresponding documentsdef predict(sents, doc):sent_id, sent_mask = get_tokens(sents,tokenizer)sent_id, sent_mask = torch.tensor(sent_id, dtype=torch.long),torch.tensor(sent_mask, dtype=torch.long)doc_id, doc_mask = get_tokens([doc],tokenizer)doc_id, doc_mask = doc_id * len(sents), doc_mask* len(sents)doc_id, doc_mask = torch.tensor(doc_id, dtype=torch.long),torch.tensor(doc_mask, dtype=torch.long)preds = model(sent_id, doc_id, sent_mask, doc_mask)return predsdef summarize(doc, model, min_sentence_length=14, top_k=4, batch_size=3):doc = doc.replace("\n","")doc_sentences = []for sent in nlp(doc).sents:if len(sent) > min_sentence_length:doc_sentences.append(str(sent))doc_id, doc_mask = get_tokens([doc],tokenizer)doc_id, doc_mask = doc_id * batch_size, doc_mask* batch_sizedoc_id, doc_mask = torch.tensor(doc_id, dtype=torch.long),torch.tensor(doc_mask, dtype=torch.long)scores = []# run predictions using some batch sizefor i in tqdm(range(int(len(doc_sentences) / batch_size) + 1)):preds = predict(doc_sentences[i*batch_size: (i+1) * batch_size], doc)scores = scores + preds.tolist()sent_pred_list = [{"sentence": doc_sentences[i], "score": scores[i][0], "index":i} for i in range(len(doc_sentences))]sorted_sentences = sorted(sent_pred_list, key=lambda k: k['score'], reverse=True)sorted_result = sorted_sentences[:top_k]sorted_result = sorted(sorted_result, key=lambda k: k['index'])summary = [ x["sentence"] for x in sorted_result]summary = " ".join(summary)return summary, scores, doc_sentences
Conclusions
In this post, we have walked through some code on how to implement extractive summarization in Pytorch. You can find a repository wil the full code here.
References
[^1]: Zero-shot learning. https://en.wikipedia.org/wiki/Zero-shot_learning.
 Neural Extractive Summarization with BERT
Neural Extractive Summarization with BERT How to Finetune BERT for Text Classification (HuggingFace Transformers, Tensorflow 2.0) on a Custom Dataset
How to Finetune BERT for Text Classification (HuggingFace Transformers, Tensorflow 2.0) on a Custom Dataset How to Implement Gradient Explanations for a HuggingFace Text Classification Model (Tensorflow 2.0)
How to Implement Gradient Explanations for a HuggingFace Text Classification Model (Tensorflow 2.0) How to Build MultiModal Recommender Systems with Tensorflow
How to Build MultiModal Recommender Systems with Tensorflow How to Build a Similar Posts Feature for Your Gatsby (JAMSTACK) Website using Machine Learning (Document Similarity)
How to Build a Similar Posts Feature for Your Gatsby (JAMSTACK) Website using Machine Learning (Document Similarity) Recent Breakthroughs in AI (Karpathy, Johnson et al, Feb 2021)
Recent Breakthroughs in AI (Karpathy, Johnson et al, Feb 2021) The Agent Execution Loop: Building an Agent From Scratch
The Agent Execution Loop: Building an Agent From Scratch