Introducing Peacasso: A UI Interface for Generating AI Art with Latent Diffusion Models (Stable Diffusion)
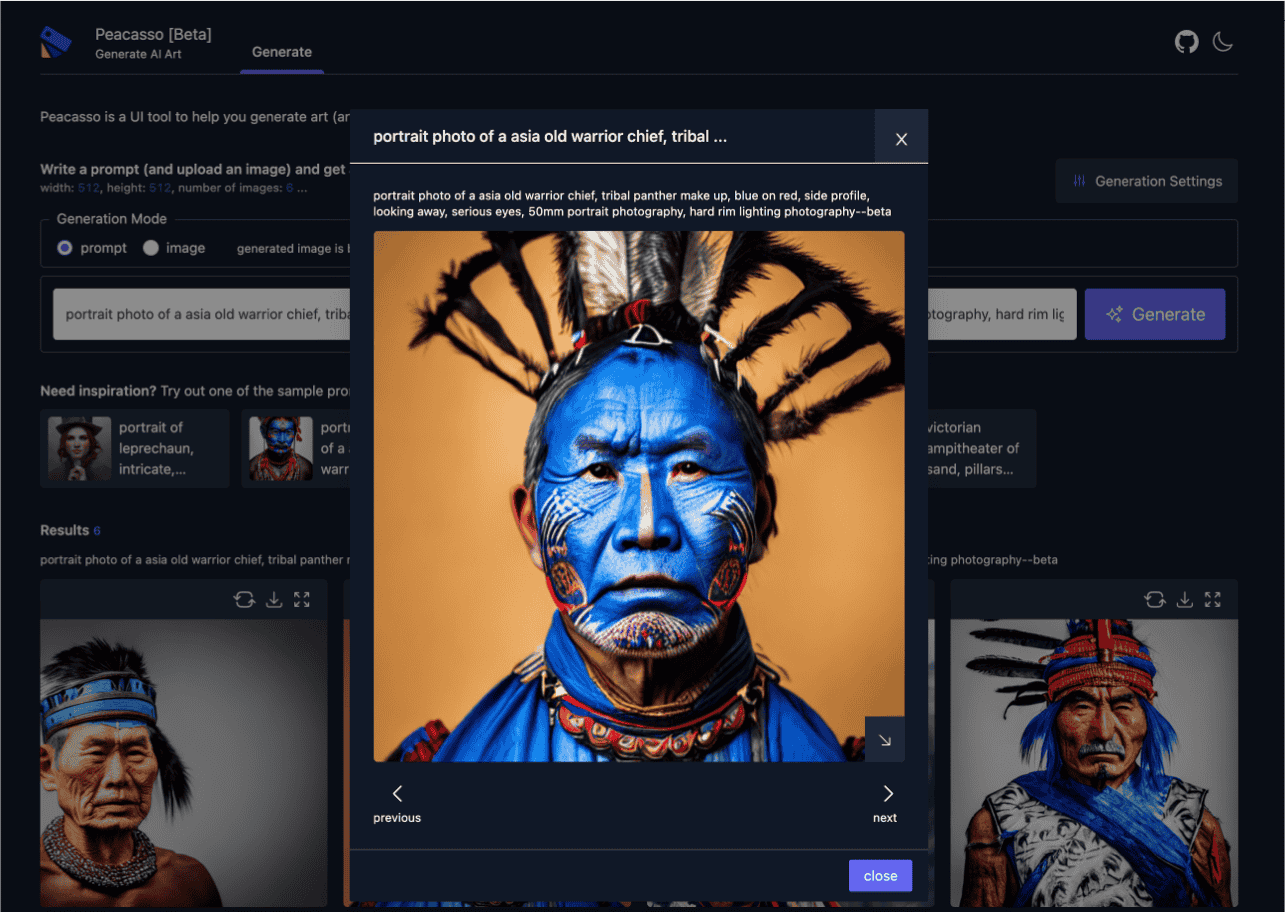
The image above was not drawn by an artist or any human. Instead an AI model (a latent diffusion model) was given a description (text) - "portrait photo of an old warrior cheif, tribal panther. make up ...." - and it generated this image. Wild!
Latent diffusion models (e.g. stable diffusion) apply a denoising process in generating high quality images based on text descriptions. While these models are powerful, designing an experience that leverages these models and truly supports the user in the creative process of image generation is still an open challenge. How do we help users find the right prompts? How do we help users explore the latent space or capabilities of the model? How do we help users iterate and refine their results? How do we help users understand the model's output?
In this post, I describe the design of Peacasso, a UI interface which should start addressing some of these questions.
Peacasso is open source on github and can be installed on your local machine (you do need a GPU though). Don't have a GPU? Try it all out in Google Colab.
Architecture
Peacasso is built as a python library two high level component.
-
Core modules: This currently includes a general image generation pipeline (text to image, image to image, mask+image to image ie. inpainting), and is implemented based on the HuggingFace diffusers library.
-
Web API: This includes backend and frontend sections. The backend web api is built with Fastapi and provides rest api endpoints for interacting with the core modules (requesting generations). The frontend is built with React (ant design and tailwind css) and provides a UI interface for interacting with the backend.
UI Interface and Features
Peacasso is a work in progress and the goal is to deliver a set of primary and experimental user interaction flows. The primary interaction flows implement core image generation modalities of latent diffusion models (text-to-image, image-to-image). The experimental interaction flows aim to explore novel interaction types and also high level application use cases (e.g., generating tiles, short videos, storytelling etc.).
Primary Flows for Image Generation
The user can provide a text prompt and several images are generated based on the prompt. As a starting point, Peacasso also provides a small gallery of prompts that the user can select from.
Peacasso currently supports :
-
Text-to-image generation: Here a prompt is provided in the form of text and the model generates an image based on the prompt.
-
Text+Image-to-image generation: The user can upload an image and a text prompt and the model generates an image based on the prompt and the image.
-
Image Inpainting: The user can upload an image, edit the image (erase portions of it which are captured as a mask over the original image) + a text prompt and the model generates an image based on the mask, the original the image and the text prompt.
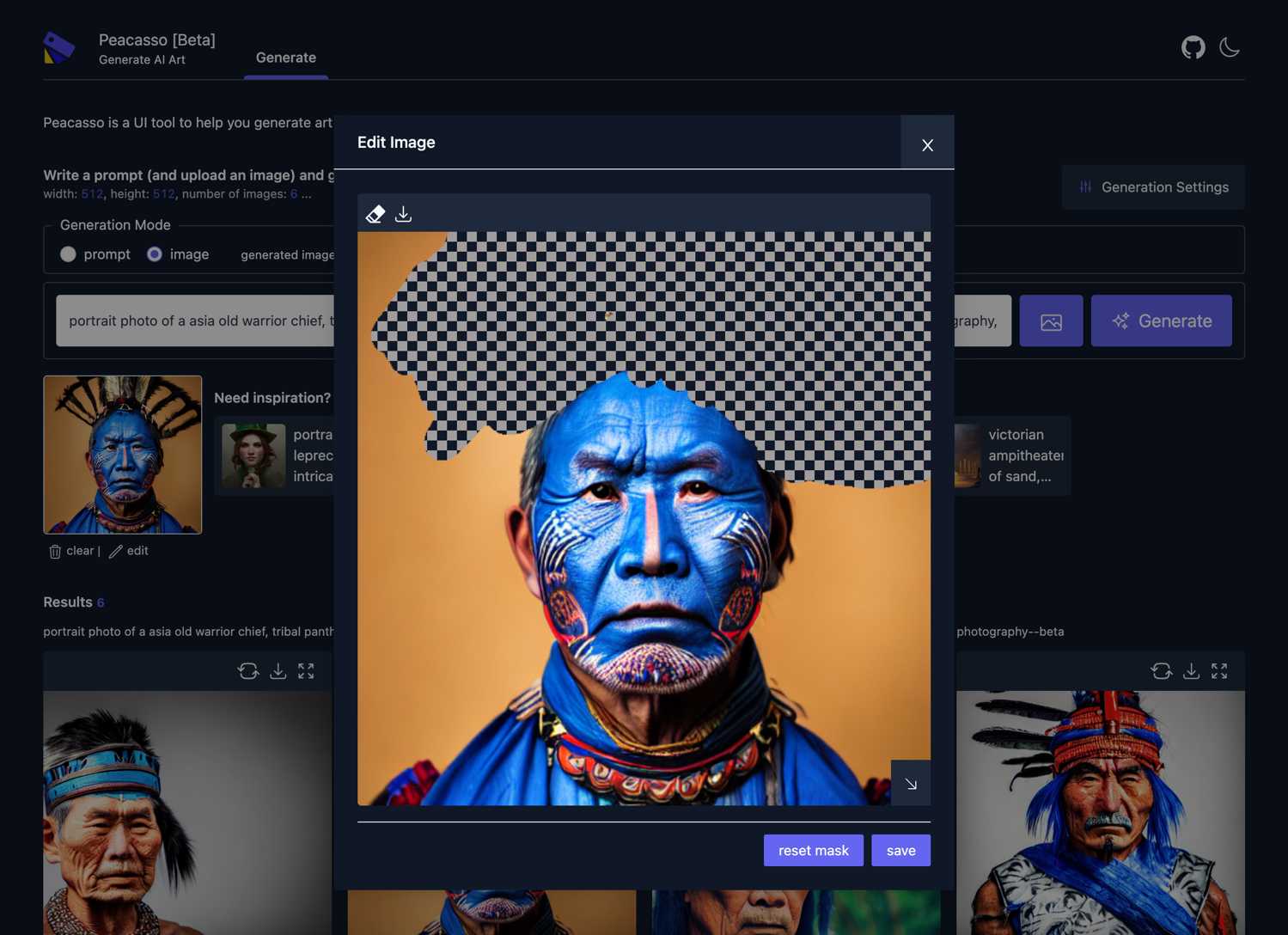

Experimental Flows
At the moment, this section is still a work in progress. The goal is to explore novel interaction types (prompt suggestion), model explanations and also high level application use cases (e.g., generating tiles, short videos, storytelling etc.).
 Designing Anomagram
Designing Anomagram ART + AI — Generating African Masks using (Tensorflow and TPUs)
ART + AI — Generating African Masks using (Tensorflow and TPUs) Latent Diffusion Models: Components and Denoising Steps
Latent Diffusion Models: Components and Denoising Steps 2023 Year in Review
2023 Year in Review Learning to Illustrate/Paint with Autodesk Sketcbook (How To)
Learning to Illustrate/Paint with Autodesk Sketcbook (How To) The Agent Execution Loop: Building an Agent From Scratch
The Agent Execution Loop: Building an Agent From Scratch How to Build MultiModal Recommender Systems with Tensorflow
How to Build MultiModal Recommender Systems with Tensorflow