2023 Year in Review

2023 was an exceptionally busy year, largely due to the swift pace of innovation in the AI space and the sheer challenge of keeping up.
So, how did the year go? My objectives for the year, as outlined in my 2022 year-in-review post, included a greater emphasis on research, writing, and community contributions, as well as learning new things and maintaining personal health/fitness.
TLDR;
This year, my personal blog writing decreased as I dedicated significant time to staying current with AI/ML developments, leaving little room for other activities. While I spent sometime researching how to improve my web dev skills (e.g., digging into state management tools like Zustand, and node based diagramming with React Flow), I wish I got to dig into more net-new technologies.
Overall, I am hopeful for, and excited about the year ahead.
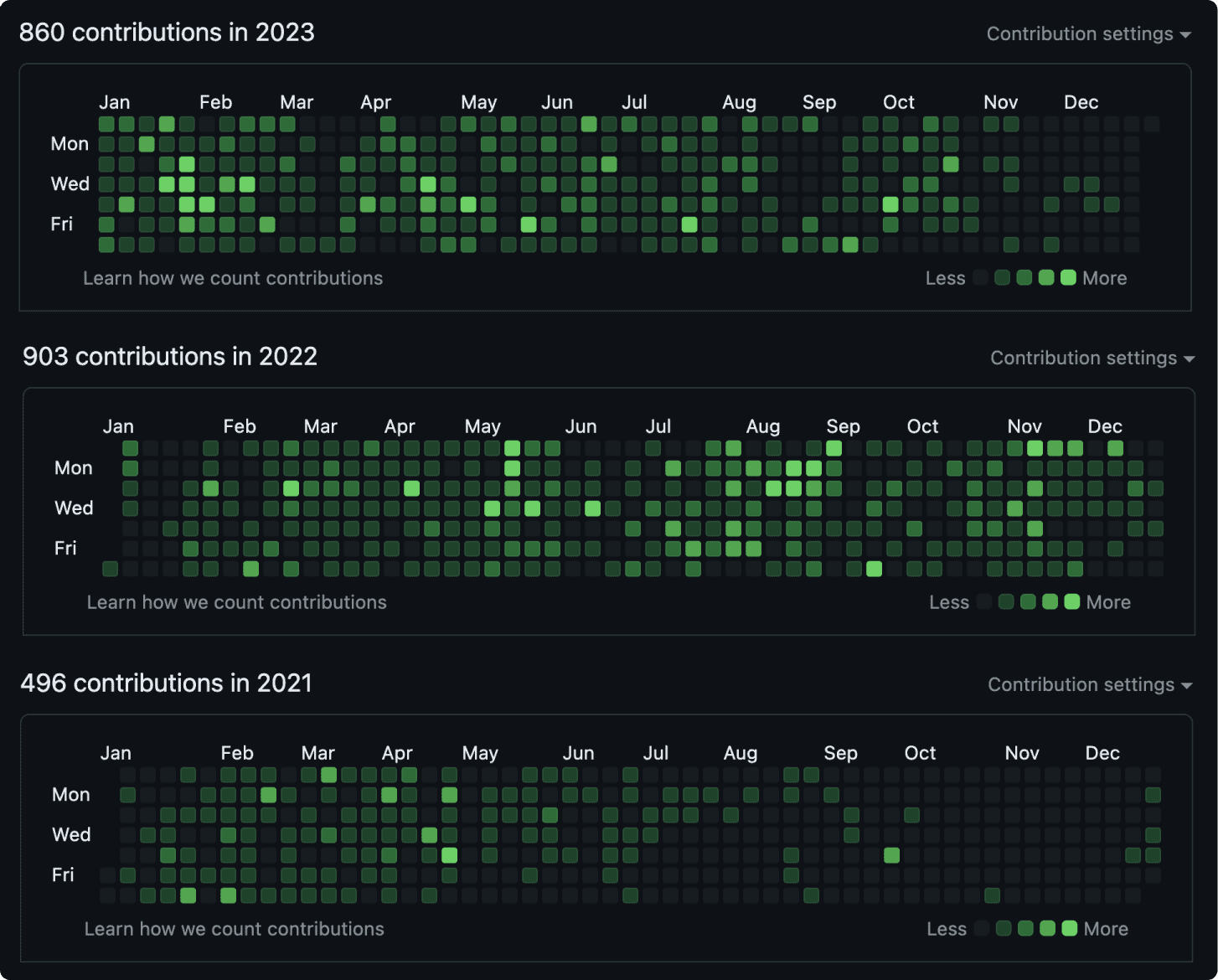

A Turbulent Year. A Busy Generative AI Year.
2023 has been a turbulent year for the tech industry, with a significant number of layoffs. The AI space also witnessed an unprecedented pace of innovation, which has led to some degree of AI anxiety.
Several important developments occurred this year in the AI space, particularly in Generative AI, that I consider highly significant. A simplification of these important events, in my opinion, includes:
- RLHF Fine-Tuning: ChatGPT demonstrated that LLMs, when fine-tuned to align with human feedback, can become overall more helpful tools. These models become even more valuable when paired with the right user experience. This has inspired dozens of research projects on how to replicate the outcome of helpful models, such as RLAIF, DPO, etc.
- OSS Models and Parameter-Efficient Fine-Tuning: Models like LLAMA and Mistral provided OSS (weights) access to competitive foundational models. Techniques like LORA and QLORA made it possible to rapidly fine-tune base foundational models on consumer GPUs. The combination of these developments has led to an explosion of experiments, research, and progress in the AI space. There are currently thousands of open-source LLMs (mostly in the 7B to 13B parameter range) on Hugging Face.
- AI and Product: There have been dozens of new product features that integrate LLMs (e.g., GitHub Copilot, Microsoft Product CoPilots, etc.), as well as startups exploring novel products and problem spaces with AI. A shout-out to all the teams that worked under tight deadlines to deliver many of the interesting results we see today.
As a research software engineer, a side effect of the surge in progress in the AI space is that I have been busy. This includes keeping up with reading new papers, running new experiments that integrate these new approaches, and rewriting existing tools to accommodate new updates, among other tasks.
Research Writing
Published 2 research papers this year at leading natural language processing research venues - ACL and EMNLP.
Victor Dibia. LIDA: A Tool for Automatic Generation of Grammar-Agnostic Visualizations and Infographics using Large Language Models. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 3) (2023): 113–126.
LIDA is a novel tool for generating grammar-agnostic visualizations and infographics using large language models (LLMs) and image generation models (IGMs). The system comprises of four modules: a SUMMARIZER that converts data into a rich but compact natural language summary, a GOAL EXPLORER that enumerates visualization goals given the data, a VISGENERATOR that generates, refines, executes and filters visualization code, and an INFOGRAPHER module that yields data-faithful stylized graphics using IGMs. LIDA provides a Python API and a hybrid user interface for interactive chart, infographics, and data story generation.
Corby Rosset, Guoqing Zheng, Victor Dibia, Ahmed Awadallah, Paul Bennett. Axiomatic Preference Modeling for Longform Question Answering. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (2023): 11445-11475.
The remarkable abilities of large language models (LLMs) like ChatGPT and GPT-4 partially stem from the post-training processes involving human preferences encoded within a reward model as part of a Reinforcement Learning from Human Feedback (RLHF) regimen. These reward models (RMs) often lack direct knowledge of why, or under what principles, the preferences annotations were made. In this study, we identify principles that guide RMs to better align with human preferences, and then develop an axiomatic framework to generate a rich variety of preference signals to uphold them. We use these axiomatic signals to train a model for the scoring answers to longform questions. Our approach yields a Preference Model with only about 220M parameters that agrees with gold human-annotated preference labels more often than GPT-4. The contributions of this work include: training a standalone preference model that can score human- and LLM-generated answers on the same scale; developing an axiomatic framework for generating training data pairs tailored to certain principles; and showing that a small amount of axiomatic signals can help small models outperform GPT-4 in preference scoring. We intend to release our axiomatic data and model.
Blog and Writing
Mixed results here. I was hoping I could write on my blog and newsletter atleast once per month (12 articles each). That did not pan out really well. Instead, I got to write:
- 5 personal blog articles (vs 16 last year)
- 6 full length newsletter posts (vs 6 posts last year)
- Multi-Agent LLM Applications | A Review of Current Research, Tools, and Challenges
- Top 5 AI Announcements (and Implications) from the 1st OpenAI DevDay
- A Defacto Guide on Building Generative AI Apps with the Google PaLM API
- Understanding Size Tradeoffs with Generative Models - How to Select the Right Model (GPT4 vs LLAMA2)?
- How to Generate Visualizations with Large Language Models (ChatGPT, GPT4)
- Practical Steps to Reduce Hallucination and Improve Performance of Systems Built with Large Language Models
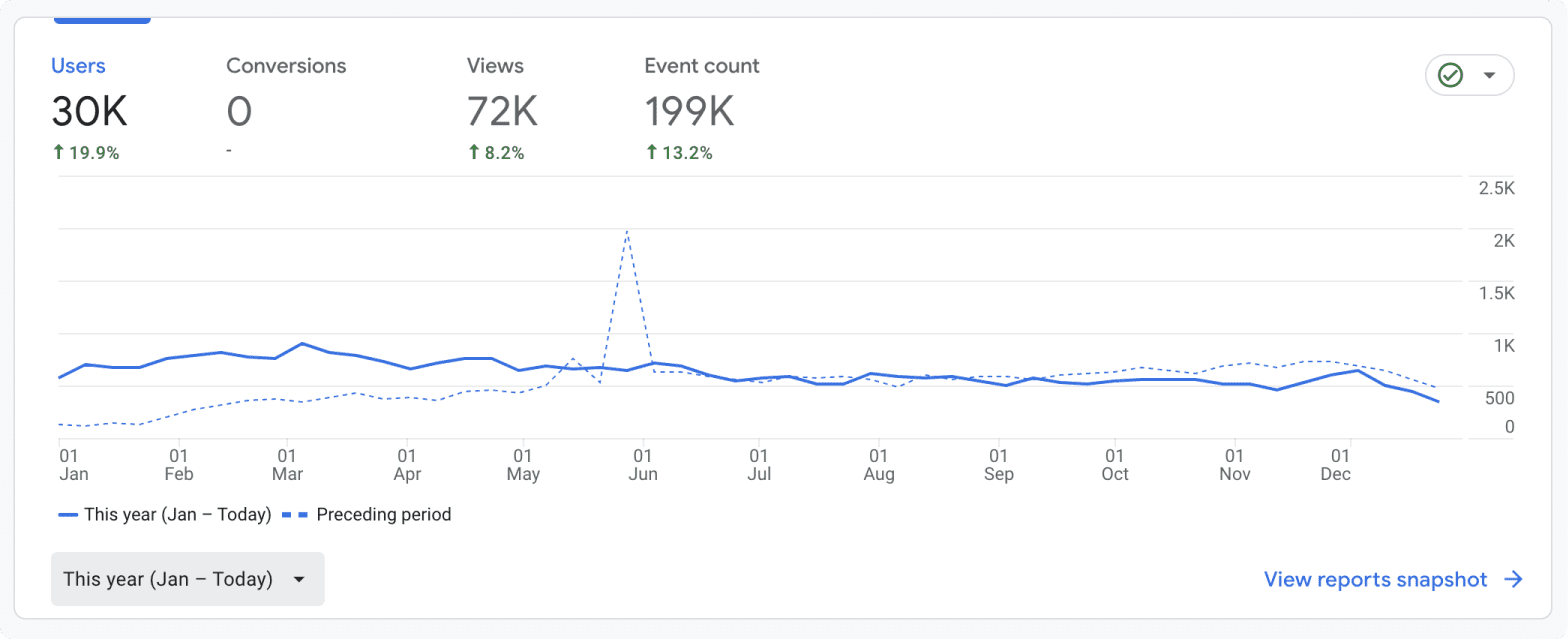
The newsletter readership did grow - from 100 subscribers to over 600 subscribers (Thank you!). Still very small, but progress. I was also hoping to make significant progress on my book (Designing with Machine Learning). Didn't make much progress here, but there is a chapter on Generative AI available.
Community
I gave 7 talks, created LIDA - an open source tool to automatically generate data using LLMs, core contributor on AutoGen - a framework for building multi-agent LLM applications.
Conferences and Talks
-
In Person Talks.
- GDG Seattle DevFest (Automated Data Visualizations)
- Keynote on AutoGen at the Ai.dev/Cassandra Summit.
-
Virtual Talks:
- Lancaster University (Automated Data Visualizations)
- Deaking University AI Festival (Automated Data Visualizations)
- Stanford (Introduction to OpenAI apis, DataViz)
- Microsoft MLADS Conference
- Snowflake BUILD Conference (Automated visualizations with LLMs and Streamlit)
OSS Contribution
LIDA - a library for automated generation of visualizations using LLMs - is definitely the most exciting OSS project I worked on this year. I built an initial version of LIDA in August 2022 (before ChatGPT, Code Interpreter), demonstrating how a chat interface paired code execution could enable novel approaches to generating visualizations. Since then, LIDA has gone on to become an OSS project (over 2000 stars as at time of writing).
LIDA was impactful to internal teams looking to apply LLMs to data visualization (designing a reliable pipeline, UX, evaluation metrics) and has been used by many external teams since becoming open source. There is still much to be studied here and I look forward to extending this work in 2024.
I am also actively contributing to building AutoGen, a framework for building multiagent LLM applications.
Learning New Skills
This year, I just have not had time to delve into any completely new areas. I tinkered around with some new javascript/React framework (e.g., Reactflow for flow diagrams, zustand for better state management, building UI interfaces with Streamlit).
Work Life Balance
-
Personal and Work Travel: Participated in two family/vacation trips this year, in addition to other personal and work-related travel.
-
Family Time Commitment: Maintained a consistent focus on family during weekends, creating many specialmemories with my son. Activities included accompanying him to Wushu classes and observing his progress through belt rankings, teaching him math concepts, working on his drawing and reading skills, and guiding him in learning to ride a bicycle. Witnessing the moment when bike riding just "clicks" after persistent practice is profoundly rewarding.
-
Physical Fitness and Well-being: I can now do a half-decent wheel pose. A bit of improvement from the glute bridge I started working on in 2022. Also got consistent with working out at least 4-5 hrs per week.
I am grateful for the opportunity at this stage in my career to balance professional work with personal enrichment. I hope to maintain this balance in the coming year.
Cheers to a Better New Year Ahead!
For 2023, I'd like to continue improving on the same things - research, writing, community contributions, learning new things, personal health/fitness. I'd love to grow the LIDA project, AutoGen project and build out some interactive tools to demonstrate some of my thoughts on the UX for Generative AI applications.
I am thankful for all who have helped make 2023 a wonderful year. Thank you! Cheers to everyone who made it to the end of the year. You did great, you are awesome, you are appreciated, you rock! Happy New Year!
 Top 10 Machine Learning and Design Insights from Google IO 2021
Top 10 Machine Learning and Design Insights from Google IO 2021 2024 Year in Review
2024 Year in Review 2018 Year in Review
2018 Year in Review 2025 Year in Review
2025 Year in Review 2021 Year in Review
2021 Year in Review 10 Predictions on the Future of Cloud Computing by 2025 - Insights from Google Next Conference
10 Predictions on the Future of Cloud Computing by 2025 - Insights from Google Next Conference Recent Breakthroughs in AI (Karpathy, Johnson et al, Feb 2021)
Recent Breakthroughs in AI (Karpathy, Johnson et al, Feb 2021)