Recent Breakthroughs in AI (Karpathy, Johnson et al, Feb 2021)
This post is a summary of my notes from the Feb 11, 2021 discussion on Clubhouse titled Recent Breakthroughs in AI. The talk was moderated by Russell Kaplan (Scale AI) and the panel included Richard Socher (You, Salesforce Research), Justin Johnson (University of Michigan, Facebook), Andrej Karpathy (Tesla). The discussion mostly looked at the novelty of transformer based multimodal models such as CLIP[^1] and DALL·E[^2] which have both shown interesting results.
Background - CLIP and DALL·E
For reference, the CLIP[^1] model was introduced by OpenAI where they efficiently learn visual concepts from natural language supervision. In addition to demonstrating the ability to generalize well to multiple real world data conditions, CLIP[^1] can be applied to any visual classification benchmark by simply providing the names of the visual categories to be recognized; similar to the “zero-shot” capabilities of GPT-2 and GPT-3.
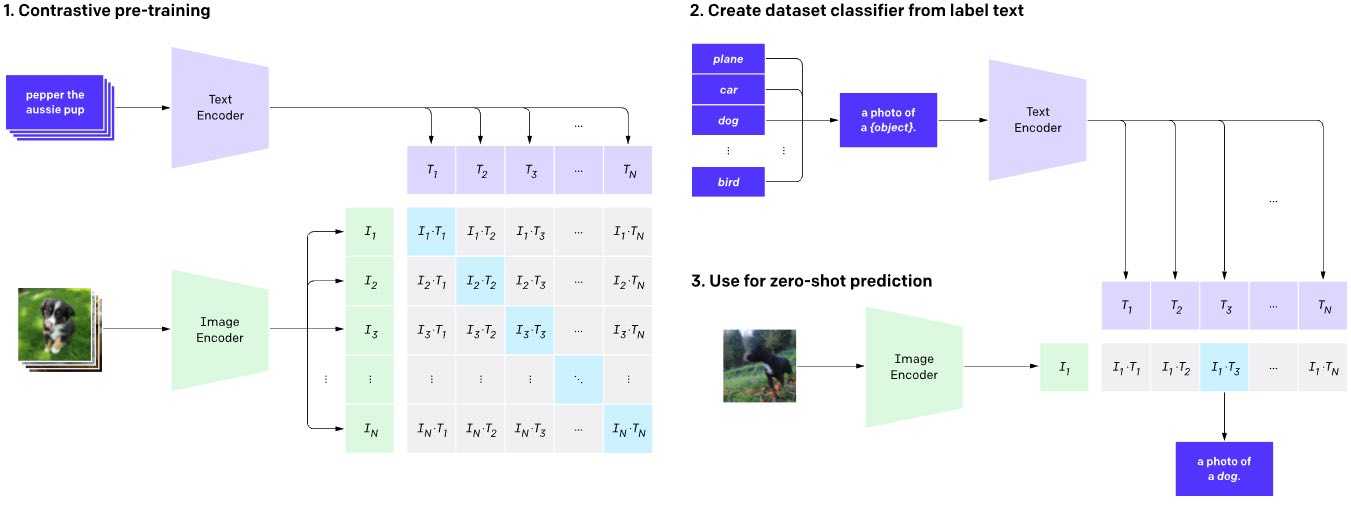
Along similar multimodal lines, DALL·E[^2] is a (12 billion parameter) model that creates images from text captions for a wide range of concepts expressible in natural language. DALL·E[^2] has a diverse set of capabilities, including "creating anthropomorphized versions of animals and objects, combining unrelated concepts in plausible ways, rendering text, and applying transformations to existing images".

The reader is particularly encouraged to read the OpenAI blog posts for CLIP[^1] and DALL·E[^2] and then corresponding papers for details on ablations studies used to demonstrate the value of the design choices for each model (DALL·E paper is yet to be published, now published[^12]. ). Both models were released by OpenAI on the same day (Jan 5, 2021).
On the Novelty of CLIP
All of the panelists agreed that both of these models were interesting and represented progress in the field. Some of the reasons include:
Improves on SOTA for Zero Shot Learning and Self Supervised Learning
CLIP provides interesting zero shot learning capabilities that can have wide application for multiple domains. It takes existing ideas from the self supervised learning literature ( e.g. Contrastive Learning - SIMCLR[^3], MOCO[^4],, SWAV[^5] Learning via Text Annotations e.g. VirTex[^6]), and massive scales them up (parameters and data!). Its a great example of minimum innovation for maximum impact.
Novelty in Data Collection Methods, Training (Objective Function, Hyperparameter)
CLIP provides new ideas on how to:
- innovate with data collection at scale - they scrape 400M image/text pairs.
- innovate on training i.e the right hyperparameters, training objectives (joint image/text representation e.g. compared to VirTex), regularization, use of transformer substrates etc to effectively train the model.
As an example, the image below shows CLIP performance (zero shot .. no examples except from the label) on multiple datasets. Hint it handsomely beats out a pretrained ResNET (pretrained on ImageNet). It succeeds in classifying adversarial images (a long open problem), sketches and renders.
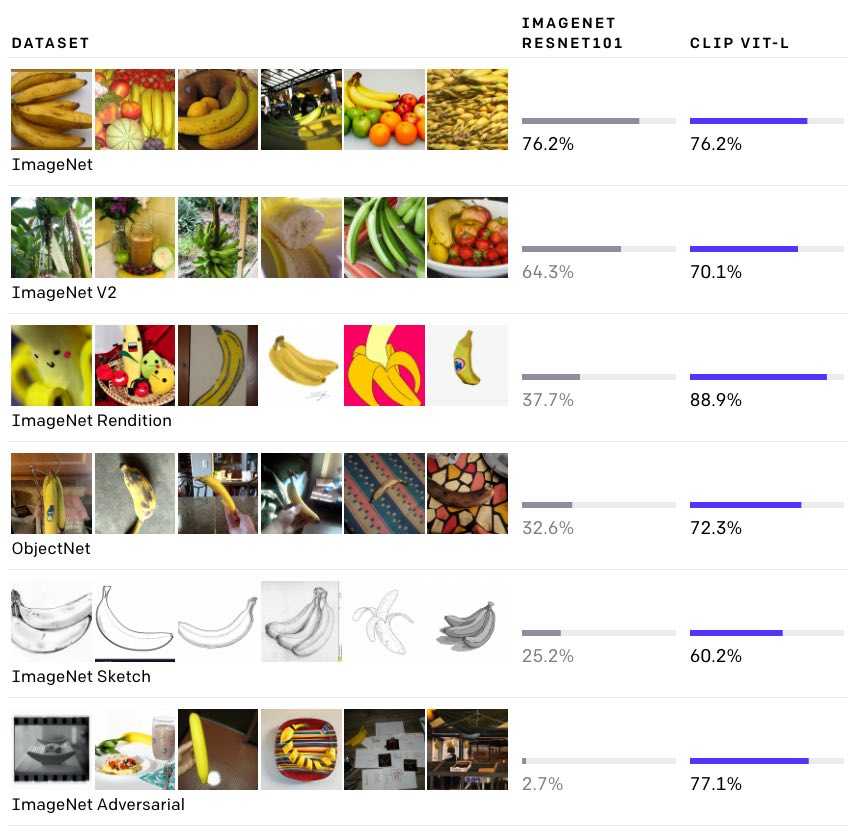
Beyond ImageNet Embeddings; Towards Real-World Generalization
Much of the work in visual representation learning are typically bootstrapped from ImageNet embeddings where we have labelled data and ground truth labels. This limits the resulting model to concepts within ImageNet's classes. In addition, the class labels are not inherently meaningful to the network (a list of random numbers). By using natural language labels (as seen in CLIP), we get representations anchored in a wide variety of real world concepts (as coverd by text in the training pairs). This enables wider generalization. Experiments in the CLIP[^1] paper support this intuition.
Transformers are Unifying the Deep Learning Model Space
A large part of the conversation acknowledged the rising importance of transformer[^7] based models and how it might be set to truly dominate the entire space of neural networks. To what degree do we expect this trend to continue? Will we drop ConvNets entirely or deprecate it in favour of transformer based representations? Perhaps!
Rise of Transformers
Andrej Karpathy provided a helpful analogy on an observed arc in the ML field (tasks/problems being consolidated into one solution), and why Transformers might be relevant for a while. I drew a diagram (below) of what this arc might look like.

- Siloed Fields (say 20 years ago): Initially , tools/methods used for NLP, CV, SPEECH processing were largely independent.
- Consolidation via Neural Networks (say last 10 years ago): Neural networks have become a shared tool for solving problems across domains. However the SOTA NN architures for each domain remained different e.g CNNs for CV, LSTMs for NLP etc.
- Unifying on Transformers (now): For the first time, Transformers have made it possible to write a few lines of code, modify it slightly to fit multiple domains (NLP -> BERT, GPT etc ; CV-> ImageGPT, Vision Transformers ViT[^10], etc; SPEECH->Wave2Vec[^11] etc ) and achieve competitive results! OpenAI has demonstrated skill in laying out out diverse problems from the Transformers perspective and showing competitive results. Interestingly, OpenAI use Transformers for both the text encoder and image encoder (Vision Transformers [^10]) in the CLIP[^1] model and show (via ablation studies) that these choices yield the best results.
What Are the Next Frontier(s)?
Data is King❗ - Data is "how you program your neural network"
How do you program a neural network (if there is such a thing)? The closest answer is data. By carefully curating your data, you can influence/guide/intuit on the behaviour of the resulting model. All panelists agreed that good data continues to be a critical but underated source of performance gains. An oldie but goodie.
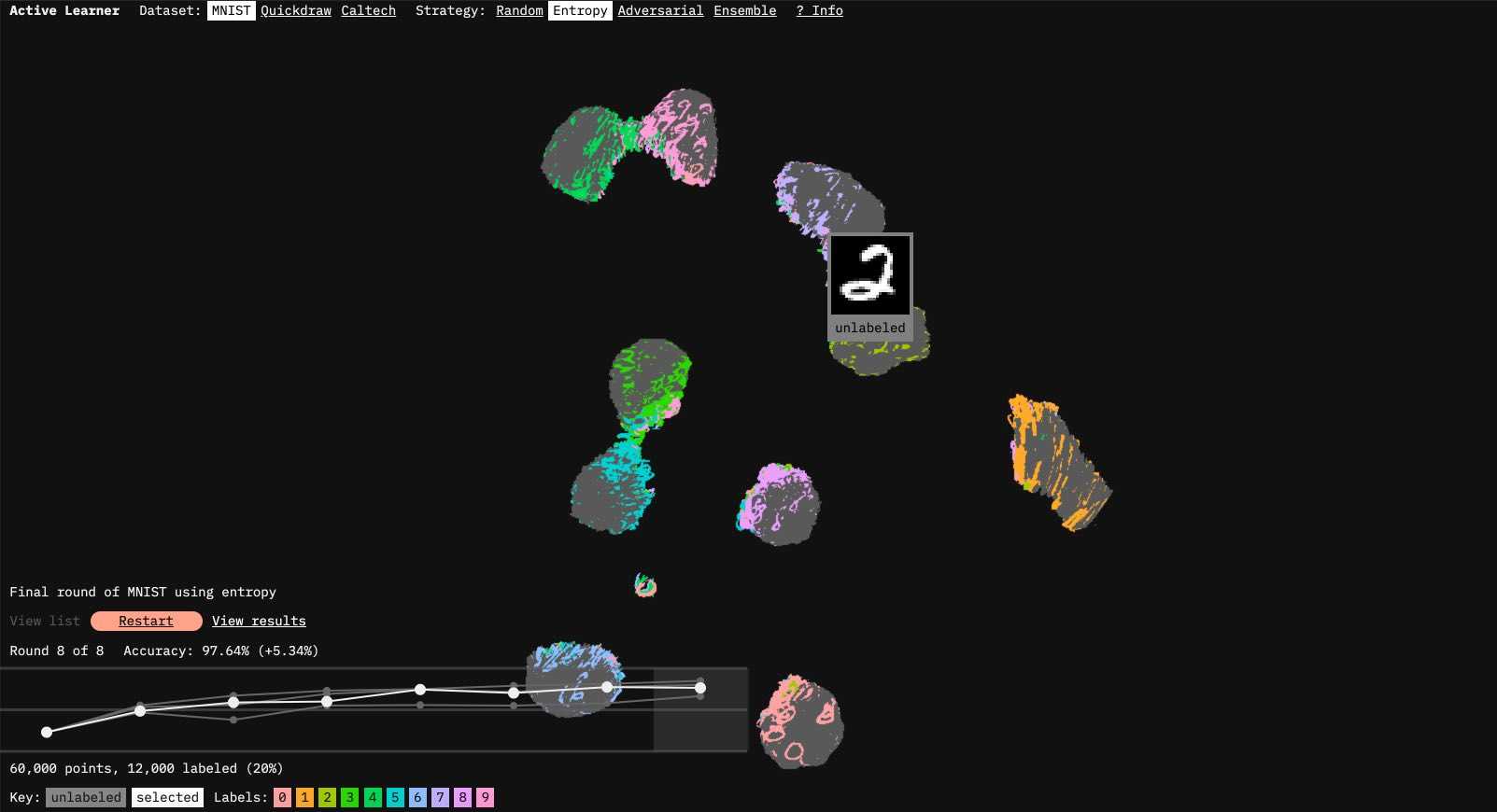
Data Curation Infrastructure - Intelligent Labelling etc
Many companies that heavily rely on data tend to have built out their own infrastructure for curating and managing data. Given that labelling is expensive, and all labels are not equally informative, a few questions arise:
- Which data points are worth labeling ?
- Which data points yield the most value wrt to a given task/objective?
While these questions have been explored within the field of Active Learning, there is potential for these problems to be further standardized with general agreement on the right approach. Companies like Snorkel AI, Scale AI, LabelBox etc, focus on this area.
Growing Focus on Software/Engineering/Infrastructure for ML
ML models (for specific tasks) are becoming fairly standardized. Companies planning to use ML in a production setting will get the most compounding return on investment by focusing on software/infrastructure/engineering (from data curation to model serving). It is also telling that companies focused on ML toolkits (make it easier to collect/curate data, train and deploy models) are attracting VC funding. Examples include Weights and Biases, HuggingFace, ScaleAI etc.
Parrallelization, Hardware and Low Level Optimization are Important!
Low level optimization (e.g. C/C++ implementations of model routines) is another area that is often overlooked, but remains very important. Models like Transformers that lend themselves well to being parralelized (especially on today's hardware platforms) are well positioned to have more impact. In practice, some algorithms may not be the best, but appear more interesting/popular because they have won the hardware lottery.
Similarly, looking towards the future, a panelist (Richard) mentioned he expects to see explorations in new objective functions, new domains (e.g. the AI economist , Protein Folding problems etc) mostly implemented with parallization in mind (async SGD).
Addressing Catastrophic Forgetting, Towards Continuous Learning.
One of the draw backs of the current approach to AI research is that each task is explored independently in silos. For example models trained to predict sentiment are not reused for translation. On one hand, this is explained by catastrophic forgetting - a known issue with neural networks - but also inhibits progress towards general purpose models.
Perhaps, one way to improve on this is to create a paradigm that enforces continous learning on a common neural substrate. How can we create a single neural substrate model that can be continuously (perhaps sequentially) trained, gets better at multiple tasks without forgetting? How do we figure out which weights to update to encode new knowledge, which weights to avoid, which waits to update to ensure we can retain previous knowledge?
This is also reminiscent of other short comings of today's neural networks - most NLP models today struggle with long text - they break down beyond ~100 tokens. We dont have models than can read long text (e.g chapters in a book) and generate meaningful summaries without loosing context. To address this, we perhaps need to innovate beyond Transformers (current SOTA) which scale quadratically wrt to sequence length.
Also, models today struggle with reasoning/logic capabilities. E.g. GPT can perform simple multiplications but struggles as the numbers get larger. Which brings us to the next point - how do we create models that can reason?
Models Capable of Logic/Reasoning
There are multiple approaches to this goal :
- Explicitly integrate built in inductive bias that help models do math. See Andor, Daniel, et al[^8], Gupta, Nitish, et al[^9].
- Scale the model massively such that it sees enough examples to achieve decent logic/reasoning capabilities.
Taking cue from how humans address logic problems (we don't solve math problems by recalling what we have seen previously, instead we run subroutines), the first approach is perhaps more promising.
New Approaches to Dataset Creation (Departing from Purely Supervised Models)
Scaling up transformer models can enable new capabilities as seen in CLIP. However, there is a limit/constraint to amount of data (text/images) that we can mine. For example, there is no 100M example dataset of summarization problems.
Given the importance of data, there is a need to innovate in how we can create high quality datasets e.g. via clever simulations etc.
Model-First Approach to Benchmarks (Not Data-First)
Today's benchmarks are structured as follows - here is some data and task, find an architecture that solves the task. What if we flip this on its head? Here is an NN model architecture, create data that solves this task? This approach might lend itself better to assembling datasets that lets us more efficiently program the model and yield better performance.
On Explainable ML
Overall, the panelists acknowledged that explainability research might be lagging other areas (e.g representation learning etc). However, explanations are hard. Even human explanations are a low dimensional approximation of our behaviour. Humans do not or cannot precisely explain their actions e.g. When making the decision to steer during driving, we do not particularly know what neurons fired, how those neurons impact motor/muscle activity and how that resulted in the steering action. Perhaps, similar low fidelity explanations might suffice for ML models? There is also the acccuracy/explainability tension especially in high-stakes situation where there is cost associated with being wrong - do we want a model that is accurate but is a black/dark box or one that is less acccurate but explainable?
Multimodal approaches to explainability are helpful.
- Sensitivity analysis is a practical/good way to make models more robust. E.g we can use CV techniques to change skin color, change zip codes etc to verify the model behaves as expected etc.
- Focus on slices of data to observe model behaviour
- Explainability (and fairness) are also social issues - social approaches apply.
Conclusion: What Might This Mean for Industry and Academia?
In my opinion, there were several interesting ideas in this discussion that might be of interest to applied researchers at industry labs, founders looking for good ideas/directions and academic researchers.
Industry Research
- New types of benchmarking (model first)?
- Transformers can unify multiple problem spaces and simplify problem solving in production.
- Focus on parrallelization or tools that advance SOTA in this space.
Startups
- Solving problems in the data creation/curation space is valuable.
- Tools for ML Model OPs e.g. versioning. Think Github for ML models (commit weight updates, roll back weight updates, quantify effect of each update on each output task etc).
- True multimodal search .e.g show me a shirt that looks like this shirt .. but has Barack Obama's face on it?
Academia
- Research in data collection and curation is impactful and understated.
- Open problems in the data labeling space. How informative is a sample (this is related to active learning) but can be more complicated when considered at scale.
- Softeningg CS concepts by making them differentiable -->
- Time to revisit Catastrophic Foregetting/ Continual Learning? Exploring the neural substrate approach? Practical solutions here will be pretty incredible!
- Tools for ML Model Versioning. Think Github for ML models (commit weight updates, roll back weight updates etc).
- Joint Embeddings for Solving Text Problems? CLIP demonstrates novel results but for vision tasks. Are there NLP tasks for which this joint model outperforms GPT-X (or current SOTA)?
Discuss this post on Twitter:
Recent Breakthroughs in AI (and why the CLIP model by OpenAI interesting!). I wrote a post summarizing my notes from the Feb 11 discussion on this topic by @russelljkaplan @karpathy @jcjohnss @RichardSocher . 🧵 Thread. https://t.co/q857pSqX0z
— Victor Dibia (@vykthur) February 16, 2021
References
[^1]: Radford, Alec, et al. "Learning transferable visual models from natural language supervision." . https://openai.com/blog/clip/
[^2]: DALL·E: Creating Images from Text. https://openai.com/blog/dall-e/
[^3]: Chen, Ting, et al. "A simple framework for contrastive learning of visual representations." International conference on machine learning. PMLR, 2020
[^4]: He, Kaiming, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. "Momentum contrast for unsupervised visual representation learning." In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9729-9738. 2020
[^5]: Caron, Mathilde, et al. "Unsupervised learning of visual features by contrasting cluster assignments." arXiv preprint arXiv:2006.09882 (2020)
[^6]: Desai, Karan, and Justin Johnson. "Virtex: Learning visual representations from textual annotations." arXiv preprint arXiv:2006.06666 (2020)
[^7]: Vaswani, Ashish, et al. "Attention is all you need." arXiv preprint arXiv:1706.03762 (2017)
[^8]: Andor, Daniel, et al. "Giving bert a calculator: Finding operations and arguments with reading comprehension." arXiv preprint arXiv:1909.00109 (2019).. EMNLP 2019 https://www.aclweb.org/anthology/D19-1609.pdf
[^9]: Gupta, Nitish, et al. "Neural module networks for reasoning over text." arXiv preprint arXiv:1912.04971 (2019). ICLR 2020
[^10]: Dosovitskiy, Alexey, et al. "An image is worth 16x16 words: Transformers for image recognition at scale." arXiv preprint arXiv:2010.11929 (2020)
[^11]: Baevski, Alexei, et al. "wav2vec 2.0: A framework for self-supervised learning of speech representations." arXiv preprint arXiv:2006.11477 (2020)
[^12]: Ramesh, Aditya, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. "Zero-Shot Text-to-Image Generation." arXiv preprint arXiv:2102.12092 (2021)
 Top 10 Machine Learning and Design Insights from Google IO 2021
Top 10 Machine Learning and Design Insights from Google IO 2021 2023 Year in Review
2023 Year in Review 2024 Year in Review
2024 Year in Review AlphaCode: Competition-Level Code Generation with Transformer Based Architectures | Paper Review
AlphaCode: Competition-Level Code Generation with Transformer Based Architectures | Paper Review 2018 Year in Review
2018 Year in Review 2021 Year in Review
2021 Year in Review State of Deep Learning for Object Detection - You Should Consider CenterNets!
State of Deep Learning for Object Detection - You Should Consider CenterNets!