Neural Extractive Summarization with BERT
This post provides an overview of extractive summarization, how it can be framed as sentence classification and implemented implemented using modern deep NLP models (BERT et al). In extractive summarization, the task is to extract subsets (sentences) from a document that are then assembled to form a summary. Abstractive summarization on the other hand might generate novel words, paraphrase original text or rewrite text (substitution, deleting, reordering etc).
Abstractive vs Extractive Summarization, Which is Better?
Abstractive summarization, while being a harder problem, benefits from advances in sophisticated transformer-based langauge models such as BERT, GPT-2/3, RoBERTa, XLNet, ALBERT, T5, ELECTRA). We can treat abstractive summarization as a sequence to sequence translation task, where the task is to translate a long document to a shorter summary (see PEGASUS [^3]). However, as these models generate summaries, there is a risk that they might synthesize new text that changes the meaning of the original text, non factual text or plain incorrect summaries. For applications where these sort of correctness errors are intolerable, extractive summarization are a potentially good fit e.g. summarization of medical documents, legal documents etc.
Pros
- Large datasets exist
- End to end training can allow a model generate grammatically correct summaries
- Models can paraphrase, similar to what humans do .
Cons
- Model can hallucinate information that is not contained in the original document or factually incorrect. This can result in summaries that are different in meaning compared to the orignal document.
Pros
- Unlikely to change the meaning of text
- In built explainability. We can visualize sentence scores; Explore gradient based approaches to compute contribution of each input token to score prediction.
Cons
- Extracted sentences can be awkward and grammatically strange when
assembled.
- Introduces additional parameters that need to be tuned. Eg senticizer, took etc
- Perhaps be more compute intensive than abstractive since we are making predictions for each sentence.
Challenges/Limitations with Summarization
Maximum Sequence Length
Neural approaches to both extractive and abstractive summarization are limited by a langauge model's ability to model long sequences (e.g. BERT has a max_sequence_length = 512 tokens). When we feed in representations of long documents, we can only use the first 512 tokens (there are recent models that offer longer input sequences e.g. reformer and longformer but are still limited).
Training Data Bias
Trained models will likely inherit any biases in the training dataset (e.g. use of click bait phrasing, focus on concepts specific to the datasource, or simply including material from the first few sentences in the summary (try out the interactive example gallery below). As an example, given that we train using data from CNN and Daily mail, there is a chance that those words appear regularly in summaries (e.g. James Dorsey exclusively told Daily mail about) and the model may tend to focus on (highly score) sentences with these words to the summary.
Evaluting Summarization Models
The quality of a summary is subjective and contextual. It is inherently hard to obtain a quantitative metrics that truly assesses the quality of a summary. There are some good heuristics or surrogate approaches we can rely on. As a starting point, we can look at the word overlap (Rouge score) between summaries generated by a model and ground truth examples which is what we do in this study. Again, take at look at the example results
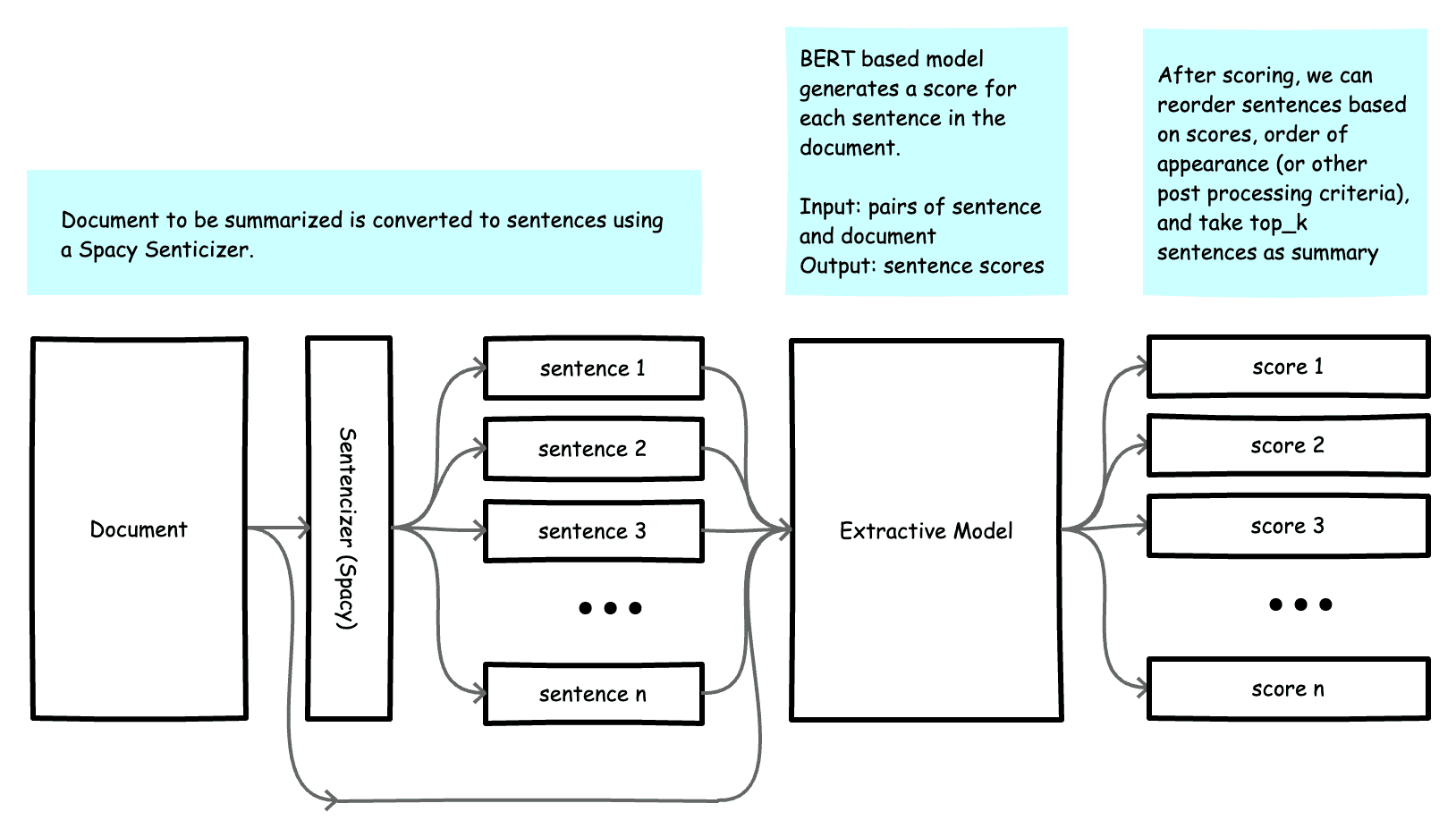
Problem Framing: Extractive Summarization as Sentence Classification
Overall, we can treat extractive summarization as a recommendation problem i.e. Given a query, recommend a set of sentences that are relevant. The query here is the document, relevance is a measure of if a given sentence belongs in the document summary.
How we go about obtaining this measure of relevance might vary (the common dilemma for any recommendation systems problem). We can select multiple problem formulations for example.
Classification/Regression.
Given input(s), output a class or some relevance score for each sentence. Here, the input is a document and a sentence in the document, the output is a class (belongs in summary or not) or a likelihood score (likelihood that sentence belongs in summary). This formulation is pairwise, i.e at test time, we need to compute n passes through the model for n sentences to get n classes/scores, or compute this as a batch.
Metric Learning
Learn a shared distance metric embedding space for both documents and sentences such embedding for documents and sentences that belong in the summary for that document are close in distance space. At test time, we get a representation of the document and each sentence, and then get the most similar sentences. This approach is particularly useful as we can leverage fast similarity search algorithms.
In this work, we will explore a classification setup which follows existing studies (e.g. Nallapati et al[^2] use RNNs for text encoding and classify each sentence). While this approach is pairwise (and compute intensive wrt to the number of sentences), we can accept this limitation as most documents have a relatively small number of sentences.
Training Dataset Construction
In this example, we will use the CNN/Dailymail dataset (contains articles and human written highlights) which has been preprocessed in the following way:
- Each article is broken down into sentences. For this sentencification task , we use a large Spacy language model. Short sentences (min_sentence_length = 14 characters) are dropped.
- Each sentence is then assigned a label - (0: not in summary, 1: in summary). Since CNN/DailyMail highlights don't contain exact extracts, the label is generated based on max Rouge score between a given sentence and each sentence in highlights (label =
max_rouge_score> threshold ?1:0). See data preprocessing notebook for details. - Data is undersampled to handle class imbalance.
Once this process is completed, we can construct our model input X as a pair (sentence, parent docuemnt) and y as the label.
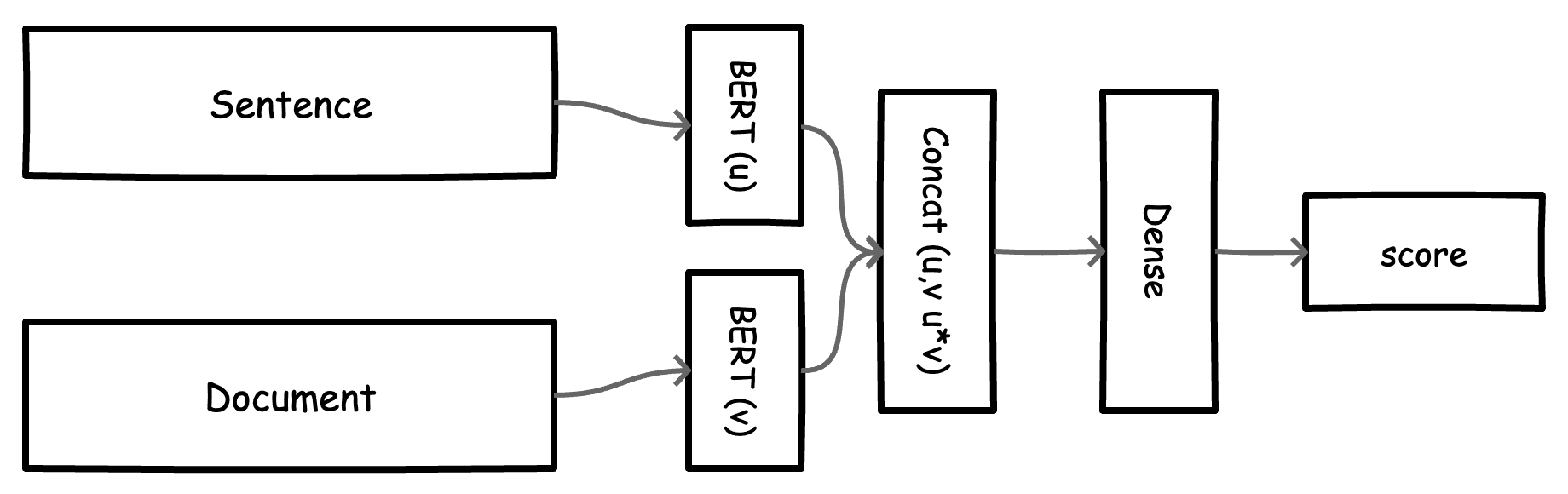
Model Implementation Overview
We want good representations for our model input (sentences and documents). For this, we explore Sentence Bert models ([^1]) that have shown good results on the task of sentence representation learning. We can then feed these representations into some classification head to predict our labels. The final model (shown above) is fairly simple:
- Get mean pooling embeddings for each input - sentence (u) and document (v)
- Concatenate both inputs (
Concat(u,v, u*v)) - Add a classification head (Dense and Dropout layers)
The entire model is then fine tuned. In the baseline, we achieve accuracy of ~86% on the train set and 74% on a held out test set.
For each new document to be summarized, inference is implemented as follows:
- Construct a list of sentences using Spacy (drop short sentences similar to training)
- Construct a batch of sentence + document pairs.
- Get score predictions for each sentence.
We can process this list of sentences and return a subset to the user as the extracted summary:
- Construct list of sentence dictionaries - sentence, score, index
- Sort list by score
- Take the
top_ksentences to be included in summary - Sort
top_ksentences by order of appearance (and any other metric) - Optionally post process each sentence for grammatical correctness, e.g. detect incomplete sentences, grammar issues, rephrase sentences etc.
Example results (Summarizing TechCrunch)
To allow for some comparison, we generated extractive and abstractive summaries using articles scraped from the front page of TechCrunch! Extractive summarization is implemented using the small sentence BERT baseline described earlier. We also benchmark against an abstractive summary which is implemented using a pretrained t5-base sequence to sequence generator model from the HuggingFace transformers library.
Click Show Article to view the content of the article being summarized.
Next Steps - Improving the Model
The approach described above is a relatively untuned baseline. There are quite a few opportunities for improvement.
Handling Data Imbalance:
Given the nature of the task (selecting a small subset of sentences in a lengthy document), for most of the sentences we get from our training dataset, the vast majority will not belong to a summary. Class imbalance! In this work, we used undersampling as a baseline strategy to handle class imbalance. A limitation of this approach is that we use a relatively small part of the total available data. We can explore other approaches that enable us to use most or all of our data. Weighted loss functions are recommended!
Sentencizer
Constructing our training dataset examples depends on the use of a sentencizer that converts documents to sentences which are used in constructing training examples. Similarly, at test time, a sentencizer is used to convert documents to sentences which are scored and used in the summary. A poor sentencizer (e.g. one that clips sentences midway) will make for summaries that are hard to read/follow. We found that using a large Spacy language model was a good starting point (the small model is not recommended). Bonus points for investing in a custom sentencizer that incorporates domain knowledge for your problem space.
Sentence and Document Representations
In this baseline, we use the Sentence Bert small model in deriving representations for sentences and documents. Other methods ( e.g. larger models) etc may provide improved results. One thing to note is that while BERT based models will yield a representation for an arbitrarily sized document, in practice they are only using the first n tokens (where = maximum sequence length for the model which is usually 512 tokens). We also found that fine tuning the underlying BERT model on the extractive summarization task yielded significantly better results than using the BERT model as a fixed feature extractor.
Tuning Hyperparameters
A project like this has many obvious and non-obvious hyperparameters that could all be tuned. Beyond the choice of BERT model architecture and training parameters (learning rate etc), we could also tune things like the label generation strategy (max_rouge_score threshold), sentencizer (choice of Spacy or other custom sentencizer), minimum sentence length to use in training/inference etc.
Conclusions
In this post, we have discussed how to build a baseline extractive summarization model using BERT based pretrained models and some approaches to improving this model. In the next post, we will review how this is implemented in code (Pytorch).
References
[^1]: Reimers, Nils, and Iryna Gurevych. "Sentence-bert: Sentence embeddings using siamese bert-networks." arXiv preprint arXiv:1908.10084 (2019). https://www.sbert.net/ [^2]: Nallapati, Ramesh, Feifei Zhai, and Bowen Zhou. "Summarunner: A recurrent neural network based sequence model for extractive summarization of documents." Thirty-First AAAI Conference on Artificial Intelligence. 2017. [^3]: Zhang, Jingqing, et al. "Pegasus: Pre-training with extracted gap-sentences for abstractive summarization." International Conference on Machine Learning. PMLR, 2020.
 How to Implement Extractive Summarization with BERT in Pytorch
How to Implement Extractive Summarization with BERT in Pytorch How to Finetune BERT for Text Classification (HuggingFace Transformers, Tensorflow 2.0) on a Custom Dataset
How to Finetune BERT for Text Classification (HuggingFace Transformers, Tensorflow 2.0) on a Custom Dataset How to Implement Gradient Explanations for a HuggingFace Text Classification Model (Tensorflow 2.0)
How to Implement Gradient Explanations for a HuggingFace Text Classification Model (Tensorflow 2.0) 2023 Year in Review
2023 Year in Review The Agent Execution Loop: Building an Agent From Scratch
The Agent Execution Loop: Building an Agent From Scratch State of Deep Learning for Code Generation (DL4Code)
State of Deep Learning for Code Generation (DL4Code) CodeXGLUE: A Machine Learning Benchmark Dataset for Code Understanding and Generation | Paper Review
CodeXGLUE: A Machine Learning Benchmark Dataset for Code Understanding and Generation | Paper Review